
☕ Tech Dive - Database Sharding
A deep dive into what is database sharding? Why do we do it and what are ways of sharding your database? Drawbacks?
Hey guys,
Hope you’re all having a fantastic weekend!
Tech Dive - Database Sharding
Most applications in 2020 can be seen as "data-driven". In other words, the app relies heavily on data pulled in from one or more sources (databases, APIs, etc.). As your application becomes more popular, the read/write load on your database will also grow at a similar pace. If your database ends up failing, your entire application will fail.
Therefore, being able to scale your database is extremely important. Scaling a service can be done in two forms: vertical or horizontal scaling.
Your first approach should be vertical scaling. If you're working with a monolith application and all your components are on the same physical server, then remove your database and put it on its own machine. As you grow, keep moving your database over to a more powerful computer.
Eventually, you'll run into a limit on vertical scaling. You've already got the most powerful computer (with Amazon Web Services RDS, for example, it is 32 vCPUs and 244 GiB of RAM). It's hard to buy a single machine that's more powerful than that. Now you have to scale horizontally.
Horizontal scaling is done by distributing your component on multiple machines. You can always add more computers to the group, so you can continue scaling horizontally forever.
A relatively easy way to implement horizontal scaling is to add read replicas. With many data-intensive applications, you'll typically be reading data a lot more than writing data. Users generally consume more data than they produce.
Therefore, add secondary database servers that replicate your primary database server. Those secondary servers are meant for reads. Whenever you write something, you first have to write it to the primary database server and then copy it over to all the secondary replicas. This makes your writes slower. The tradeoff is that your reads are much faster since you have multiple servers that can process the reads.
Eventually, you will have trouble scaling the write operations as well. Then it may make more sense to consider something like sharding.
Sharding is breaking up your data into smaller chunks called shards. Typically you'll be breaking down your data using horizontal partitioning where you maintain the table schema and columns, but each shard will contain a certain amount of the rows of your database. As a sidenote, vertical partitioning is when you split up your table's schema and columns.

Sharding can be implemented at the Application Layer (meaning your web app will maintain a list of all the database shards and make sure it's writing data to the correct shard) or it can be done by the database (some database management systems don't have sharding functionality built-in, however).
Sharding Architectures
There are multiple ways of implementing sharding in your applications. We’ll go over three popular methods of doing it. Each of these methods comes with its own tradeoffs.
Key Based Sharding
You take a column from your data and plug the values from that column into a hash function to determine which shard the data should go to. The mechanics of how this works is similar to a hash table.
You might take something like a customer ID, ZIP code, or something and hash that value. This column will be the shard key. It should be static (meaning that a row's shard key should never change).

Range Based Sharding
You select a column from your data that can be categorized in some way. Then you create ranges from that column and make each range a shard.
An example might be location (each country is a shard), date (each month is a shard), price (every $100 increment is a shard), etc.

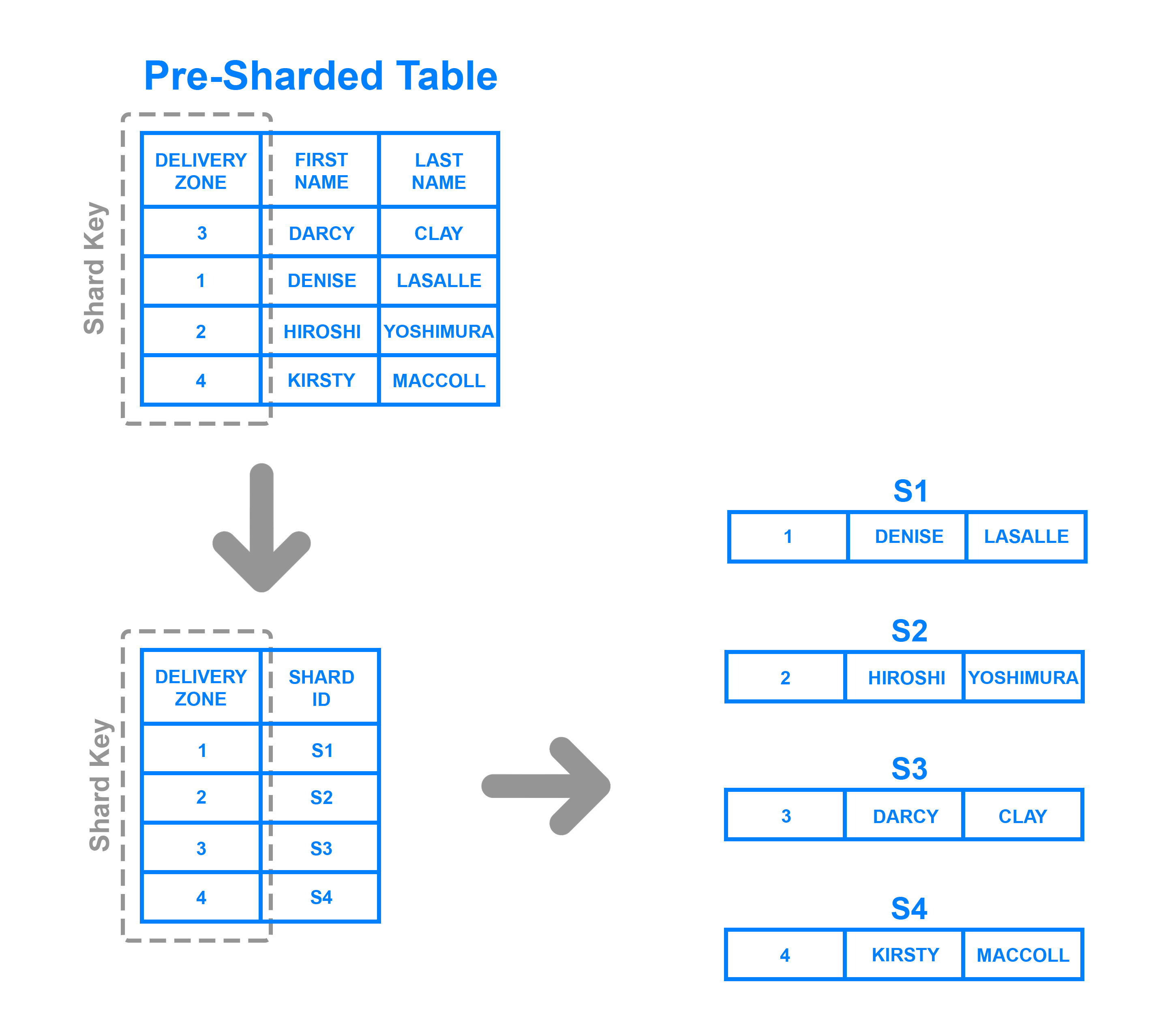
Lookup Table Based Sharding
A third way of implementing sharding is by using a lookup table (or hash table).
Like we did in key-based sharding, you'll set one column of your data as the shard key. Then, you can randomly assign rows to different shards and remember which shard contains which row with a lookup table.
Drawbacks
The main drawback of sharding is the complexity of implementing it. Sometimes, it can be relatively simple, especially if your Database Management System already implements it. Other times, it can be a major pain in the ass.
Additionally, sharding will add complexity to your workflow. Previously, you only had one endpoint for your database. Now, you have multiple endpoints… one for each shard.
One thing to watch out for is unbalanced shards, where one shard is getting far more reads/writes than the other shards. An example might be if you’re using Range Based sharding and you create one shard for users in the United States and another for users in Belgium. If your app has more US-based users, then that shard will get a lot more read/writes than your Belgium shard! That will cause scalability issues.
Hope you enjoyed this! Feel free to reply with any questions/feedback.