


☕ The Architecture Behind the World's Largest Developer Site...
Hi Everyone,
Hope you’re all having a fantastic day!
Stack Overflow was recently acquired, so we’ll be talking about
The system architecture behind Stack Overflow
Stack Overflow’s Business Model
The Stack Overflow Acquisition
Today’s interview question is from Google and the previous solution is on building a balanced binary search tree from a sorted array.
Industry News
Stack Overflow sold for $1.8 Billion Dollars to Prosus
In 2008, Joel Spolsky and Jeff Atwood launched Stack Overflow, a website meant for programmer Q&A. It took them 8 weeks to build the first version (MVP) and the growth after they launched was astonishing. Today, Stack Overflow is the 46th most heavily engaged website in the world (according to Alexa web analytics) and the company has expanded into the Stack Exchange network with Q&A sites on economics, art, chemistry, physics and much more.
In terms of how Stack Overflow makes money, they generate revenue from 3 main sources…
Stack Overflow Talent - Stack Overflow runs a recruiting platform for software developers. They’ve already helped placed tens of thousands of developers into jobs and have thousands of jobs currently unfilled on their platform.
Stack Overflow Ads - Stack Overflow integrates display ads into the website. They don’t rely on a third party ad network for advertisers, instead building their own Ad platform.
Stack Overflow Enterprise - Stack Overflow Enterprise is the exact same codebase as stackoverflow.com. However, the solution is meant to be a Stack Overflow that companies can implement for their own organizations. So specific questions about the company codebase, work from home policy or tech stack/choices can all be aggregated and indexable.
Read More about Stack Overflow’s Business Model
Stack Overflow’s Architecture
The Essence of Stack Overflow’s Architecture is contained in this diagram. Just note, Stack Overflow’s architecture blog post was last updated in 2016, so parts of this might be out of date.
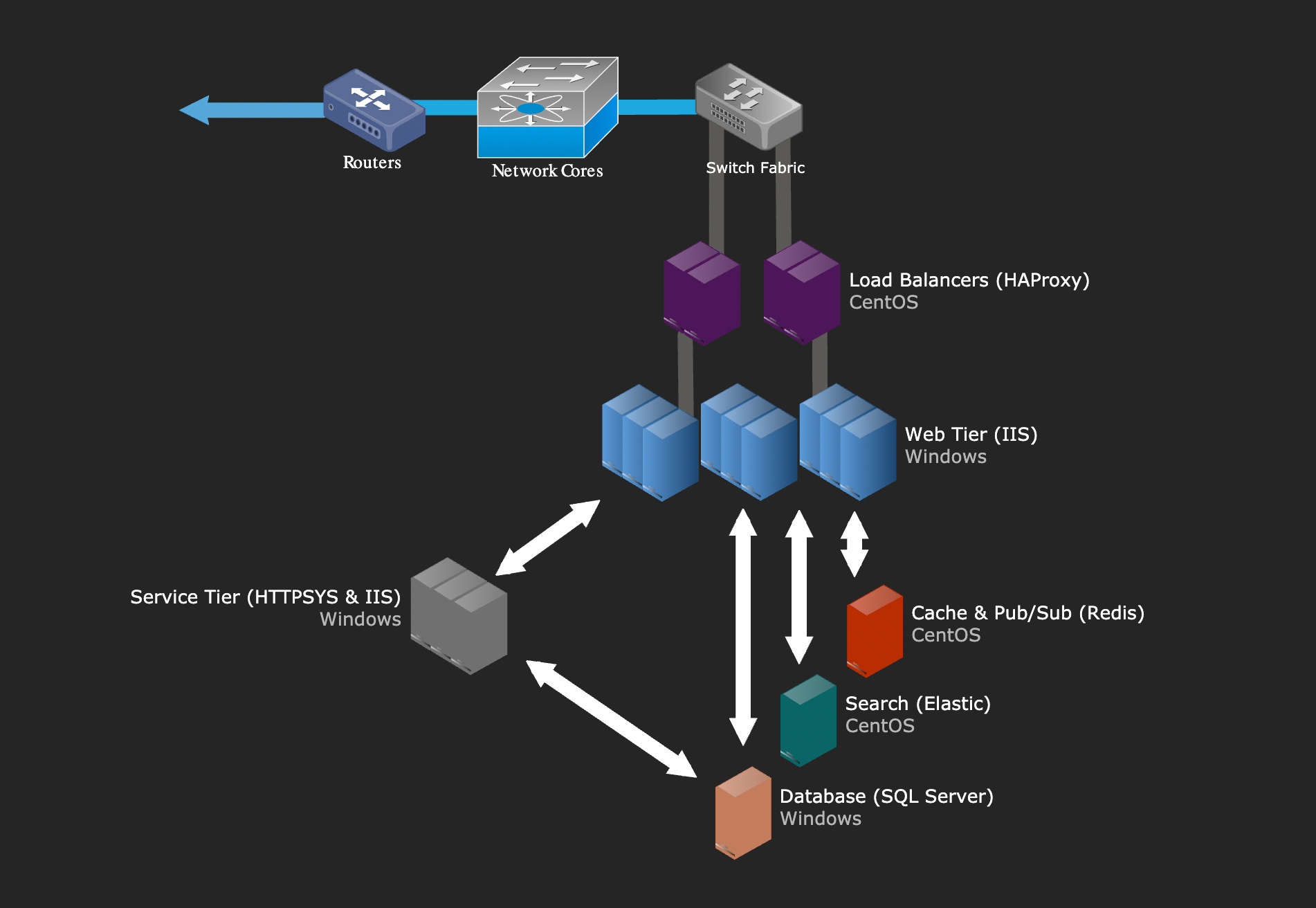
Network
The first component of a web service is DNS (giving the correct ip address for stackoverflow.com).
Stack Overflow uses CloudFlare for DNS hosting because of their extremely low latency (11 ms due to their massive network of data centers).
However, Stack Overflow also has their own DNS servers that serve as a back up.
S.O. then has several ISPs that direct the traffic to their routers. The traffic is then sent through the routers (and switch) to the Load Balancers.
Load Balancers
Stack Overflow uses several Load Balancers to direct the traffic to their multiple web servers.
The Load Balancers are running HAProxy on CentOS (an open source Linux distribution that was forked from Red Hat Enterprise Linux).
The Load Balancers also handle rate limiting to prevent DoS attacks.
Web Tier
Stack Overflow uses 9 web servers for their primary applications and 2 web servers for meta applications (these numbers may have changed since the article was published).
Their primary applications include Stack Overflow and all the other Stack Exchange sites. The websites meta.stackoverflow.com and meta.stackexchange.com are the meta applications that are run on the 2 other web servers.
When the article was written, Stack Overflow was quite over provisioned with the amount of computing resources they had available. They did this for headroom (for growth) and redundancy.
Service Tier
The Service Tier consists of servers that run internal services to support the production Web Tier.
They handle the tag engine (responsible for managing tags) and the Providence API.
The Providence project is a machine learning project at Stack Overflow that analyzes their traffic logs to assign simple labels (“web developer”, “java developer”, etc.) for each person who visits the Stack Overflow website.
This is used for recommending questions on the home page and better matching users with job postings.
You can read more about the Providence project here.
Cache & Pub/Sub
Stack Overflow has an L1 and L2 caching system.
L1 refers to HTTP Cache on their web servers (or whatever application is in play).
L2 refers to Redis (key value database) servers where values are stored in the Protobuf format.
When a web server gets a cache miss in both L1 and L2, it will fetch the value from source (a database query or API call) and then put the result in both local cache and Redis.
The Redis servers are also used for Pub/Sub (Publish & Subscribe) where one server can publish a message and all other subscribers can receive it.
Stack Overflow uses the Pub/Sub mechanism to clear L1 caches on other servers when one web server does a removal.
Search
Stack Overflow uses Elasticsearch for the /search route, calculating related questions and suggestions when asking a question.
The main reasons they picked Elasticsearch over something like SQL full-text search were scalability and pricing. Elastic was cheaper and had more features.
Database
Stack Overflow uses SQL Server as their single source of truth. In 2016, they used 2 SQL Server clusters, where each cluster had 1 master and 2 replicas.
The first SQL Server cluster hosts Stack Overflow, Sites, and their Mobile databases.
In 2016, the first cluster consisted of several Dell R720X servers, each with 384GB of RAM, 4TB of PCIe SSD space, and 2x 12 cores.
The second SQL Server cluster hosts their Talent/Recruiting site, Chat, their Exception log and every other Stack Exchange Q&A site.
In 2016, the second cluster consisted of a set of Dell R730xd servers, each with 768GB of RAM, 6TB of PCIe SSD space, and 2x 8 cores.
For a more detailed breakdown of the Stack Overflow Architecture, check out the original blog post by Nick Craver!
Interview Question
You are given an array that contains an expression in Reverse Polish Notation.
Return the result from evaluating the expression. You can assume the expression will always be valid.
Input - [“2”, “3”, “+”, “3”, “*”]
Output - 15 because ( (2 + 3) * 5)
Input - [“4“, “5“, “/“, “30“, “+“]
Output - 30.8 because ( (4 / 5) + 30)
Here’s the question in LeetCode.
We’ll send a detailed solution tomorrow, so make sure you move our emails to primary, so you don’t miss them!
Gmail users—move us to your primary inbox
On your phone? Hit the 3 dots at the top right corner, click "Move to" then "Primary"
On desktop? Back out of this email then drag and drop this email into the "Primary" tab near the top left of your screen
Apple mail users—tap on our email address at the top of this email (next to "From:" on mobile) and click “Add to VIPs”
Previous Solution
As a refresher, here’s the last question
You’re given a sorted array of integers as input (sorted in ascending order).
Convert the array to a height balanced BST.
Solution
When you’re looking to solve a tree related question, your first thought should be around recursion. Is there a way that recursion can help you here?
We want to create a height-balanced BST, so if we start with the first item in the list and create a node, and continue down… we’ll end up with a tree that looks like a linked list. Searching for elements will take O(n).
Instead, we should start with the middle of the list. Then, we have an (approximately) equal number of elements that will go on the right and the left.
We create a new node where the value is equal to the middle node. This will be our root node.
Then, we recursively call our createBST function to create BSTs for the items that are to the left of the middle node and another BST for the items that are to the right of the middle node.
Then, we set the root’s left pointer to the left BST and the right pointer to the right BST.
After, we can just return the root.
The base case is if the given list is empty. Then we can just return None.
Since slicing a list takes O(s) time (where s is the length of the slice), we’ll be doing this process by just keeping track of low and high indices. This way, we don’t have to keep taking slices of the list.
You can view the Python code with test cases here.