


A dive into LLVM and Compilers (Plus Docker)
Hey Everyone,
Today we’ll be talking about
The LLVM Project and how it works
An introduction to Compiler design
Issues that the LLVM Project seeks to solve
How LLVM-based compilers are designed
An introduction to Docker
What is a Hypervisor and why is it useful
The Why for Containers
Docker and Kubernetes
Plus, a couple awesome tech snippets on
How Facebook tests their tests for flakiness
Using Deep Learning to create music
Improvements to Type Guards in TypeScript
We also have a solution to our last coding interview question, plus a new question from Amazon.
Quastor Daily is a free Software Engineering newsletter sends out FAANG Interview questions (with detailed solutions), Technical Deep Dives and summaries of Engineering Blog Posts.
An introduction to Compilers and LLVM
LLVM is an insanely cool set of low-level technologies (assemblers, compilers, debuggers) that are language-agnostic. They’re used for C, C++, Ruby, C#, Scala, Swift, Haskell, and a ton of other languages.
This post goes through an introduction to compiler design, the motivations behind LLVM, the design of LLVM and some extremely useful features that LLVM provides. We’ll be giving a summary below.
Back in 2000, open source programming language implementations (interpreters and compilers) were designed as special purpose tools and were monolithic executables. It would’ve been difficult to reuse the parser from a static compiler to do static analysis or refactoring.
Additionally, programming language implementations usually provided either a traditional static compiler or a runtime compiler in the form of an interpreter or JIT compiler.
It was very uncommon to see a language implementation that had supported both, and if there was then there was very little sharing of code.
The LLVM project changes this.
Introduction to Classical Compiler Design
The most popular design for traditional static compilers is the three-phase design where the major components are the front end, the optimizer, and the back end.

Front End
The front end parses the source code (checking it for errors) and builds a language-specific Abstract Syntax Tree.
The AST is optionally converted to a new representation for optimization (this may be a common code representation, where the code is the same regardless of the input source code’s language).
Optimizer
The optimizer runs a series of optimizing transformations to the code to improve the code’s running time, memory footprint, storage size, etc.
This is more or less independent of the input source code language and the target language
Back End
The back end maps the optimized code onto the target instruction set.
It’s responsible for generating good code that takes advantage of the specific features of the supported architecture.
Common parts of the back end include instruction selection, register allocation, and instruction scheduling.
The most important part of this design is that a compiler can be easily adapted to support multiple source languages or target architectures.

Porting the compiler to support a new source language means you have to implement a compiler front end for that source language, but you can reuse the optimizer and back end.
The same applies for adding a new target architecture for the compiler. You just have to implement the back end and you can reuse the front end and optimizer.
Additionally, you can use specific parts of the compiler for other purposes. For example, pieces of the compiler front end could be used for documentation generation and static analysis tools.
The main issue was that this model was rarely realized in practice. If you looked at the open source language implementations prior to LLVM, you’d see that implementations of Perl, Python, Ruby, Java, etc. shared no code.
While projects like GHC and FreeBASIC were designed to compile to multiple different CPUs, their implementations were specific to the one source language they supported (Haskell for GHC).
Compilers like GCC suffered from layering problems and leaky abstractions. The back end in GCC uses front end ASTs to generate debug info and the front end generates back end data structures.
The LLVM project sought to fix this.
LLVM’s Implementation of the Three-Phase Design

In an LLVM-based compiler, the front end is responsible for parsing, validating, and diagnosing errors in the input code.
The front end then translates the parsed code into LLVM IR (LLVM Intermediate Representation).
The LLVM IR is a complete code representation. It is well specified and is the only interface to the optimizer.
This means that if you want to write a front end for LLVM, all you need to know is what LLVM IR is, how it works, and what invariants it expects.
LLVM IR is a low-level RISC-like virtual instruction set and it is how the code is represented in the optimizer. It generally looks like a weird form of assembly language.
Here’s an example of LLVM IR and the corresponding C code.

Now, the optimizer stage of the compiler takes the LLVM IR and optimizes that code.
Most optimizations follow a simple three-part structure:
Look for a pattern to be transformed
Verify that the transformation is safe/correct for the matched instance
Do the transformation, updating the LLVM IR code
An example of an optimization is pattern matching on basic math expressions like replacing X - X with 0 or (X*2)-X with X.
You can easily customize the optimizer to add your own optimizing transformations.
After the LLVM IR code is optimized, it goes to the back end of the compiler (also known as the code generator).
The LLVM code generator transforms the LLVM IR into target specific machine code.
The code generator’s job is to produce the best possible machine code for any given target.
LLVM’s code generator splits the code generation problem into individual passes- instruction selection, register allocation, scheduling, code layout optimization, assembly emission, and more.
You can customize the back end and choose among the default passes (or override them) and add your own target-specific passes.
This allows target authors to choose what makes sense for their architecture and also permits a large amount of code reuse across different target back ends (code from a pass for one target back end can be reused by another target back end).
The code generator will output target specific machine code that you can now run on your computer.
For a more detailed overview and details on unit testing, modular design and future directions of LLVM, read the full post!
Quastor Daily is a free Software Engineering newsletter sends out FAANG Interview questions (with detailed solutions), Technical Deep Dives and summaries of Engineering Blog Posts.
Tech Snippets
Probabilistic flakiness: How do you test your tests? - Facebook maintains an enormous series of automated regression tests that cover all their products and apps. They run these tests at each stage of the development process to detect regressions early.
However, tests will also deteriorate! Automated tests become unreliable (also known as flaky) as the codebase evolves and produce false signals that undermine engineer trust in the testing process.
Therefore, Facebook Engineering has created a measure of test flakiness: the probabilistic flakiness score (PFS). This measure looks at the previous history of a test, changes in the codebase and other factors to determine the probability that a test is unreliable.
Using Deep Learning to create Music - This is a review paper (summarizes the current state of research) for music generation with deep learning models.
Architectures used include Variational Auto-Encoders (VAEs), Generative Adversarial Networks (GANs), Transformers, Long Short-Term Memory (LSTMs).
The paper gives a general view of the music composition process (and basic music principles) for the philistines out there. Then, the paper goes into state-of-the-art methods for music composition, deep learning models for multi-instrument music and methods/metrics for evaluating the output of a music generation model. It also goes through open questions and areas for further research.
Type Guards and Control Flow Analysis in TypeScript 4.4 - TypeScript is quickly becoming one of the most popular programming languages out there as a statically typed alternative to JavaScript.
TypeScript 4.4 was recently released and this post goes into Type Unions (where a variable can be one of multiple predefined types) and Type Guards (TypeScript looks to see if you’ve already checked the type of a variable using an if statement and typeof).
The post describes how TypeScript 4.4 improves these features.
Tech Dive - Docker
What is a Hypervisor? Why is it useful?
In the old days, you could only run a single application on a single server. Running multiple applications could be dangerous since the two apps might interfere with each other. One app could modify the file system in a way that the other didn’t expect, causing the other application to crash. Or, one app could depend on a specific version of MySQL, while the other app needed a different version. In a worst case scenario, one app might be written by a malicious user, who’s intentionally trying to get the other app to fail.
This single app - single server configuration becomes especially expensive if you’re trying to run a cloud computing business. When a user starts off, they definitely won’t be able to utilize the full power of the server, so you’re left wasting a ton of computational power.
Hypervisors solve this issue! A hypervisor is computer software that can create and run a virtual machine. A virtual machine is an emulation of the computer system, and runs its own operating system inside of the host machine (the host machine is running the hypervisor to manage the virtual machine). The virtual machine is completely sandboxed, and anything you do in the virtual machine can’t affect the host computer or any other virtual machines the host computer is running. You basically get your own OS.
Now, a cloud computing business can just run a hypervisor on their powerful servers, and the hypervisor will spin up a new virtual machine whenever a user wants to run an application on that server.
You might also run a hypervisor on your home computer if you want to quickly test out a new operating system. You can install VirtualBox on your Windows computer and run a copy of Ubuntu inside one of VirtualBox’s Virtual Machines on top of Windows.
What are Containers?
Going back to our cloud computing business, do we really need to spin up an entire virtual machine every time a user wants to use our server? Spinning up virtual machines is expensive, and virtual machines come with a bunch of protections that aren’t really needed. Each virtual machine is gigabytes in size and takes minutes to spin up! Users are typically just packaging and running a single application on each virtual machine, so it’s a massive waste to create and bundle an entirely new OS.
What if we could use something more lightweight?
This is where containers come in. A Container is just a package for code for the application and all the dependencies that are needed. Each container shares the host OS and does not require its own OS. This allows containers to be spun up much faster and each container takes up much less space!
What is Docker?
Now, when you have containers running on a computer, you’ll need some software to manage them. You’ll need a program to spin up new containers, manage their resource sharing, and shut them down. This program is called a container engine. If you’re into analogies… Container Engine is to Container as Hypervisor is to Virtual Machine.
One extremely popular container engine is the Docker Engine. The Docker Engine is open source and is maintained by Docker, Inc!
The Docker Engine uses a Docker image as a blueprint for how to build the container. The Docker image is just a static file and is very lightweight. You can download various docker images on Docker Hub. You can download Docker Images to run Redis, Node, MongoDB and a bunch of other software.
In order to build Docker Images, you need a Dockerfile. A dockerfile is just a text file with a series of commands that tell the OS how to build the container.
What is Kubernetes
Over the last couple of years, we’ve had a trend from Monolith architectures to Microservices. Rather than have your entire application running in a single application, you’ll break down the individual components (database, authentication, payment, logging, etc.) into different individual services, and expose each individual service with a REST API.
Each service is typically run in it’s own individual container and you’ll have to run several “copies” for each service for scalability (horizontal scaling).
Orchestrating this workflow and making sure the right containers are running at the right time is a hard job! You can end up with a workflow of thousands of containers!
This is where Kubernetes comes in. Kubernetes was originally made at Google and is a platform for “automating deployment, scaling and operations of application containers across clusters of hosts”.
It can be used in conjunction with Docker, where Docker Engine is used to individually boot up and manage the containers.
Quastor Daily is a free Software Engineering newsletter sends out FAANG Interview questions (with detailed solutions), Technical Deep Dives and summaries of Engineering Blog Posts.
Interview Question
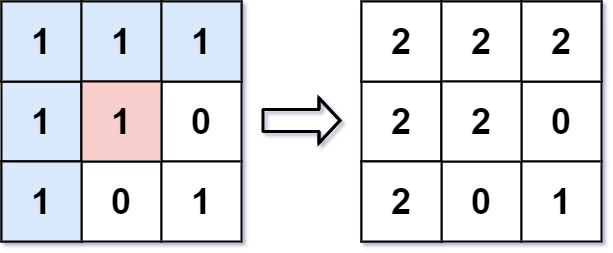
An image is represented by an m x n integer grid called image where image[i][j] represents the pixel value of the image.
You are given an image grid as well as three integers: sr, sc, and newColor.
You should perform a flood fill on the image starting from the pixel image[sr][sc].
To perform a flood fill, start at the starting pixel and change it’s original color to newColor.
Then, change the color of any pixels connected 4-directionally to the starting pixel that have the same original color of the starting pixel.
After, fill the color of any pixels connected 4-directionally to those pixels that also have the same original color.
Return the modified image after performing the flood fill.
Here’s the question in LeetCode.
We’ll send the solution in our next email, so make sure you move our emails to primary, so you don’t miss them!
Gmail users—move us to your primary inbox
On your phone? Hit the 3 dots at the top right corner, click "Move to" then "Primary"
On desktop? Back out of this email then drag and drop this email into the "Primary" tab near the top left of your screen
A pop-up will ask you “Do you want to do this for future messages from quastor@substack.com” - please select yes
Apple mail users—tap on our email address at the top of this email (next to "From:" on mobile) and click “Add to VIPs”
Previous Solution
As a reminder, here’s our last question
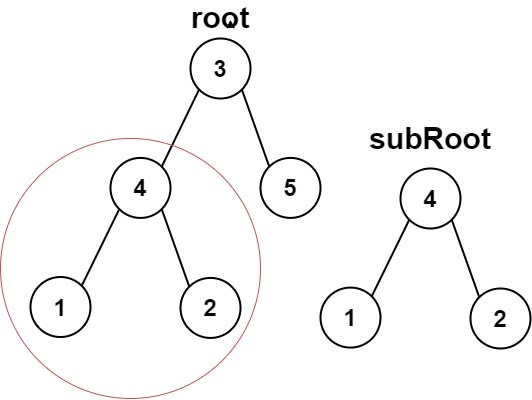
You are given the roots of two binary trees.
Return true if the second tree is a subtree of the first.
Example
Input: [3,4,5,1,2], [4,1,2]
Output: True
Here’s the question in LeetCode.
Solution
There are quite a few ways to solve this question.
One way is to find the preorder representation of both trees, convert them to strings and then see if the subtree’s preorder string is a substring of the other tree’s string.
Finding the preorder representations and converting them to strings takes linear time. The string search (to see if one if a substring of the other) also takes linear time.
Here’s the Python 3 code.
