
A One Person Startup's Tech Stack
Hey Everyone,
Today we’ll be talking about
Introduction to the Theory of Computation
An awesome undergraduate-level textbook on the Theory of Computation (it’s free to read).
What is Computational Theory?
An overview of the 3 areas: Complexity Theory, Computability Theory and Automata Theory
The Tech Stack Behind a One-Person Internet Company
ListenNotes’ website requirements and traffic
ListenNotes’ tech stack & design philosophy
Plus, a couple awesome tech snippets on
A guide on How to write unmaintainable code
A lecture on Brain Machine Interfaces
Building a fast, concurrent database in Rust (with a lecture and paper explaining the design)
We have a solution to our last coding interview question on Tries, plus a new question from Google.
Quastor Daily is a free Software Engineering newsletter sends out FAANG Interview questions (with detailed solutions), Technical Deep Dives and summaries of Engineering Blog Posts.
Introduction to the Theory of Computation
This is a fantastic (free) undergraduate-level textbook on the Theory of Computation.
We’ll be giving a (very) brief intro to the Theory of Computation below.
Computational Theory revolves around the question of “What are the fundamental capabilities and limitations of computers?”
The goal is to develop formal mathematical models of computation that are useful frameworks of real-world computers.
An example of a model is the RAM (Random-access Machine) Model of Computation which is useful for computational complexity analysis.
When you’re finding the Big O (worst-case time complexity) of an algorithm, you’re using the RAM model to make assumptions about the runtime of certain operations (assigning a variable is constant time, basic operations are constant time, etc.)
Computational Theory can be split into 3 main areas
Complexity Theory - This area aims to classify computational problems according to their degree of “difficulty”.
A problem is called “easy” if it is efficiently solvable.
An example of an easy problem is to sort a sequence of 1,000,000 numbers.
On the other hand, an example of a hard problem is to factor a 300-digit integer into it’s prime factors. Doing this would take an unattainable amount of computational power.
With complexity theory, you also want to give a rigorous proof that a computational problem that seems hard is actually really hard.
You want to make sure that the problem is hard and not that the problem is actually easy but you’re using an inefficient algorithm.
Computability Theory - This area aims to classify computational problems as being solvable or unsolvable.
This field was started in the 1930s by Kurt Gödel, Alan Turing and Alonzo Church.
As it turns out, there are a great many computational problems that cannot be solved by any computer program. You can view a list of some of these problems here.
Automata Theory - This area deals with the definitions and properties of different types of computational models.
Examples of such models are
Finite Automata - used in text processing, compilers and hardware design.
Context-Free Grammars - used to define programming languages and in AI
Turing Machines - form a simple abstract model of a “real” computer, like the one you’re using right now.
Automata Theory studies the computational problems that can be solved by these models and tries to find whether the models have the same power, or if one model can solve more problems than the other.
The textbook delves into all 3 of these areas so check it out if you’re interested!
Tech Snippets
How to Write Unmaintainable Code - This is a hilarious set of essays on how you can write the most unmaintainable code possible.
Obviously, the essays are tongue in cheek but they’re a useful collection of anti-patterns that you should avoid.
Topics discussed include how to pick ambiguous variable names, ignore standard libraries and roll your own, testing is for cowards and document how not why.
Lecture on Brain Machine Interfaces - There’s a ton of fascinating research going on around Brain-Machine Interfaces, where you can build a device that analyzes brain signals and translates them into commands for a computer.
This lecture is part of MIT’s course on The Human Brain, from Spring 2019.
Building a fast, concurrent database in Rust - Noria is an open source storage backend written in Rust that’s designed for read-heavy applications.
Noria pre-computes and caches relational query results so that reads are extremely fast. It also automatically keeps the cache up-to-date as the underlying data changes.
This talk is from Jon Gjengset (a PhD student at MIT’s Parallel and Distributed Operating Systems Group) on Rust and Noria.
He covers
Overview of Rust
Basics of Rust concurrency
The architecture of Noria
If you’d like to learn more about Noria, check out the paper a group at MIT published on it’s implementation.
Quastor Daily is a free Software Engineering newsletter sends out FAANG Interview questions (with detailed solutions), Technical Deep Dives and summaries of Engineering Blog Posts.
The Boring Technology Behind a One-Person Internet Company
Listennotes is a podcast search engine and database started by Wenbin Fang. The site gets nearly 2 million visits per month (according to SimilarWeb) and is maintained entirely by Wenbin (he’s the only employee).
Wenbin wrote a blog post in 2018 on the technology stack he uses to power the site and we’ll be summarizing it here. Some parts of the tech stack have been changed (and the site has scaled significantly since the post was written), but it’s still quite instructive.
Website Requirements
Listen Notes provides two things to end users:
The ListenNotes.com website for podcast listeners. It has a podcast search engine, a podcast database, Listen Later playlists and Listen Clips where you can clip segments of a podcast. It also has Listen Alerts where you get an email notification if a specified keyword is mentioned in a new podcast.
The ListenNotes API, where developers can use it to search podcasts and get other data about them. The server has to track API usage, collect money from paid users, etc.
Tech Stack
As of May 2019, ListenNotes ran on 20 production servers on AWS. The servers are set up to make horizontal scaling simple.
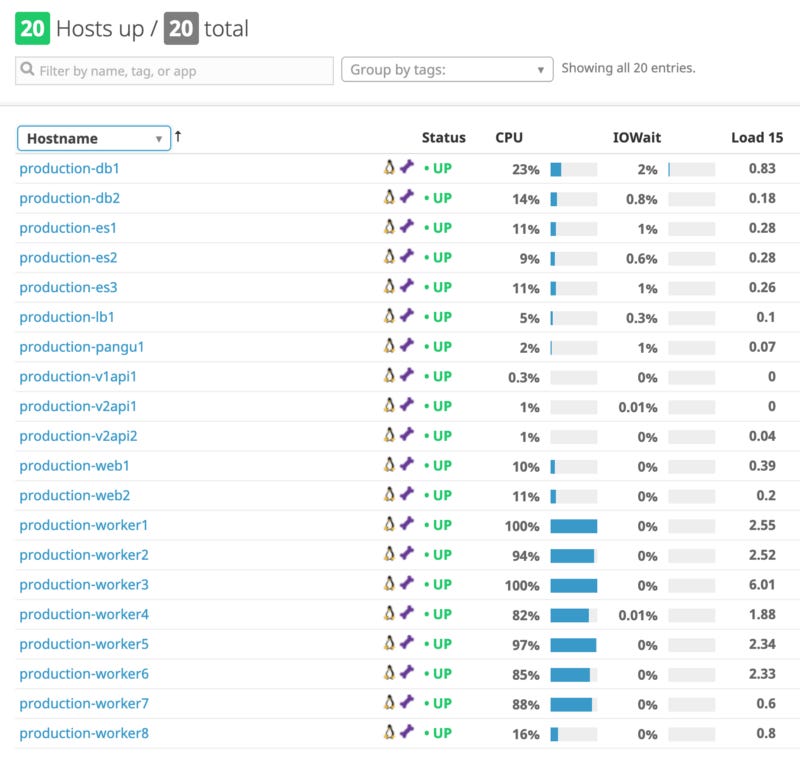
production-web servers web traffic for ListenNotes.com
production-api serves API traffic
production-db runs PostgreSQL. There are 2 servers in a master/slave configuration.
production-es runs an Elasticsearch cluster for search the podcasts (the podcasts are transcribed using the Google speech-to-text API)
production-worker runs offline processing tasks like episode/podcast recommendations, podcast search result rankings, etc.
production-lb is the load balancer.
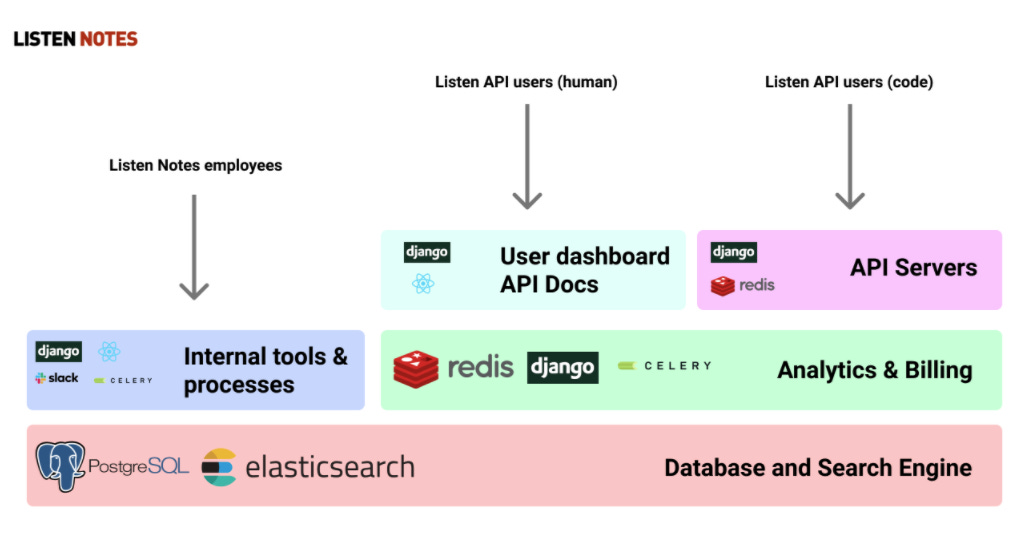
The backend is written in Django with Ubuntu as the OS of choice.
The data store is Postgres. Wenbin had a lot of development and operational experience with Postgres from his past projects, so that’s the main reason he picked it.
He also uses Redis for things like caching, stats, etc.
Elasticsearch is used for indexing podcasts and serving search queries.
Wenbin subscribes to the monolithic repo philosophy so there’s only one listennotes repo which contains all the frontend and backend code (and various scripts). It is hosted on a GitHub private repo.
Frontend
The web frontend for ListenNotes is built with React, Redux, Webpack, etc.
Most web pages are half server-side rendered and half client-sided rendered. The server-side rendered part provides the boilerplate for the web page, and the client-side rendered part is the interactive web app.
ListenNotes provides an audio player so you can listen to a podcast as you browse the site, and the audio player is a modified version of react-media-player.
DevOps
To quickly provision machines, Wenbin uses Ansible. He has a couple of YAML files that specify what type of servers need to have what configuration files and what software.
He can then spin up a server with all the correct configuration files & software with just one click.
He also uses Ansible to deploy code to production.
The tech stack is sophisticated enough to run a SaaS application with millions of users but it’s also simple enough so that Wenbin can maintain the entire thing by himself.
Read the full blog post for more details.
Interview Question
You are given a doubly-linked list where each node also has a child pointer.
The child pointer may or may not point to a separate doubly linked list.
These child lists may have one or more children of their own, and so on, to produce a multilevel data structure.
Flatten the list so that all the nodes appear in a single-level, doubly linked list.
Here’s the question in LeetCode.
We’ll send a detailed solution in our next email, so make sure you move our emails to primary, so you don’t miss them!
Gmail users—move us to your primary inbox
On your phone? Hit the 3 dots at the top right corner, click "Move to" then "Primary"
On desktop? Back out of this email then drag and drop this email into the "Primary" tab near the top left of your screen
Apple mail users—tap on our email address at the top of this email (next to "From:" on mobile) and click “Add to VIPs”
Previous Solution
As a reminder, here’s our last question
Design a data structure that supports adding new words and finding if a string matches any previously added string.
Your data structure should implement two methods
addWord(word) - Adds word to the data structure
search(word) - Returns true if there is any string in the data structure that matches word. word may contain dots where a dot can be matched with any letter (a dot represents a wildcard).
Here’s the question in LeetCode
Solution
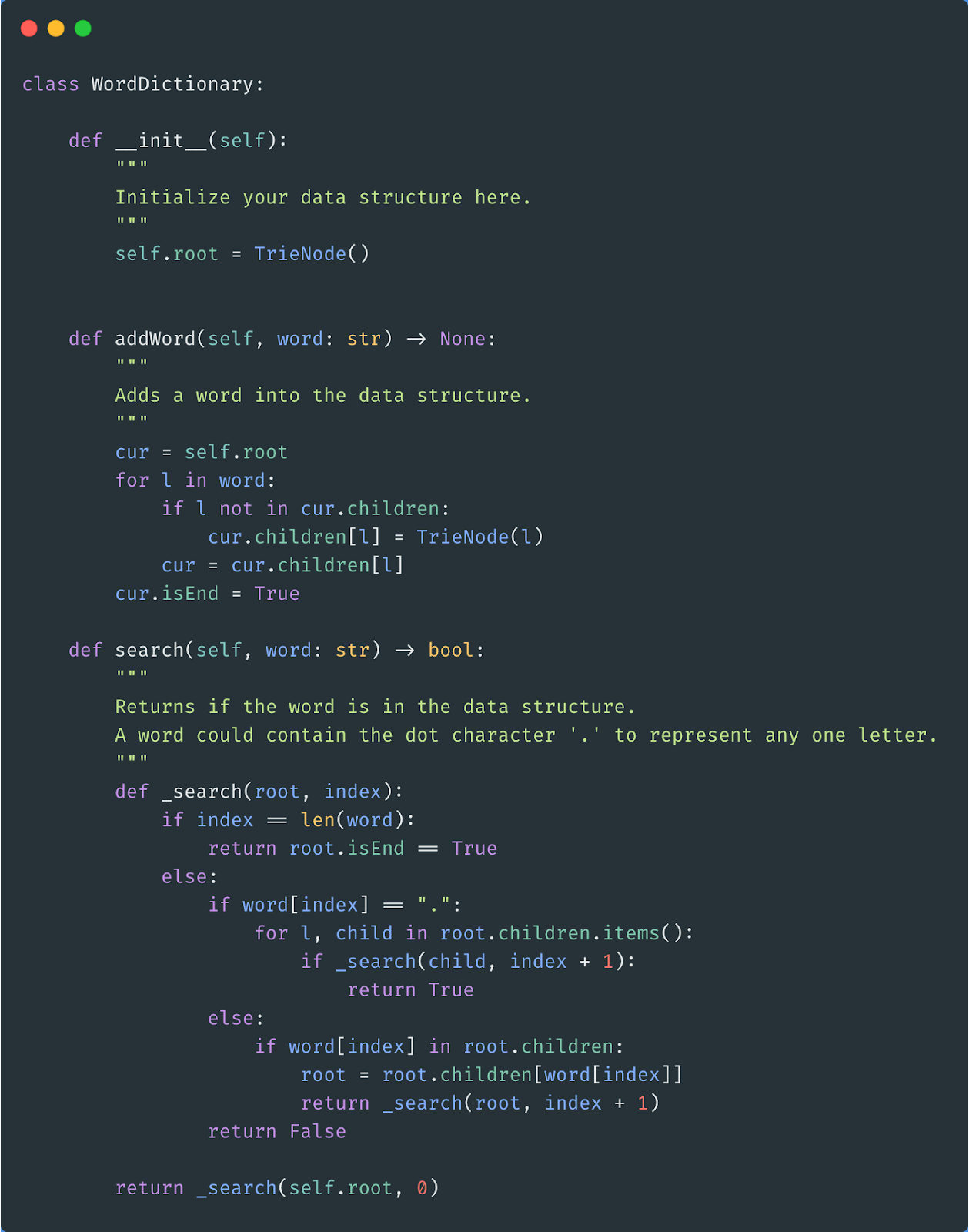
We can solve this question using the Trie data structure.
In order to build a trie, we’ll create another class called TrieNode, where each instance represents a node in our trie.
TrieNode will contain a variable called val, which will be the letter in the dictionary that this node represents.
It will also have a hash table called children, which keeps track of all the child nodes for this TrieNode.
Also, it’ll have a boolean variable called isEnd. isEnd will keep track of whether this TrieNode is the last word for any of the words in our dictionary.
This is helpful if we have a word in our dictionary like apple. If we want to search our collection of words for the word app, we want to make sure our program doesn’t falsely return True because the word apple is in our collection.
Here’s the Python 3 code for TrieNode

Now, we have to create the WordDictionary class.
This class will have 3 methods
__init__ - a constructor
addWord(word) - add a word to our word dictionary
search(word) - search for a word in our word dictionary
__init__
In our constructor, we’ll create the root node for the trie data structure that will hold our words.

addWord
Inside of our addWord function, we want to add the word to our trie.
We can do this by iterating through all the letters in our word.
As we iterate through the word, we’ll also create a path for that word in our trie (or iterate through the path if it already exists).
At the end of the path, we’ll set the isEnd flag to True, to indicate that this node represents the end of a word in our dictionary.

search
The search function does a depth-first search on our trie, looking for the given word.
If the word contains a “*”, then our DFS function will look through all the children for that specific node.
What’s the time and space complexity of the functions in our solution? Reply back with your answer and we’ll tell you if you’re right/wrong.
We also have one of our previous tech snippets in case you missed it!
A browsable Petascale Reconstruction of the Human Cortex
A connectome is a map of all the neural connections in an organism’s brain. It’s useful for understanding the organization of neural interactions inside the brain.
Releasing a full mapping of all the neurons and synapses in a brain is incredibly complicated, and in January 2020, Google Research released a “hemibrain” connectome of a fruit fly - an online database with the structure and synaptic connectivity of roughly half the brain of a fruit fly.
The connectome for the fruit fly has completely transformed neuroscience, with Larry Abbott, a theoretical neuroscientist at Columbia, saying “the field can now be divided into two epochs: B.C. and A.C. — Before Connectome and After Connectome”.
You can read more about the fruit fly connectome’s influence here.
Google Research is now releasing the H01 dataset, a 1.4 petabyte (a petabyte is 1024 terabytes) rendering of a small sample of human brain tissue.
The sample covers one cubic millimeter of human brain tissue, and it includes tens of thousands of reconstructed neurons, millions of neuron fragments and 130 million annotated synapses.
The initial brain imaging generated 225 million individual 2D images. The Google AI team then computationally stitched and aligned that data to produce a single 3D volume.
Google did this using a recurrent convolutional neural network. You can read more about how this is done here.
You can view the results of H01 (the imaging data and the 3D model) here.
The 3D visualization tool linked above was written with WebGL and is completely open source. You can view the source code here.
H01 is a petabyte-scale dataset, but is only one-millionth the volume of an entire human brain. THe next challenge is a synapse-level brain mapping for an entire mouse brain (500x bigger than H01) but serious technical challenges still remain.
One challenge is data storage - a mouse brain could generate an exabyte of data so Google AI is working on image compression techniques for Connectomics with negligible loss of accuracy for the reconstruction.
Another challenge is that the imaging process (collecting images of the slices of the mouse brain) is not perfect. There is image noise that has to be dealt with.
Google AI solved the imaging noise by imaging the same piece of tissue in both a “fast” acquisition regime (leading to higher amounts of noise) and a “slow” acquisition regime (leading to low amounts of noise). Then, they trained a neural network infer the “slow” scans from the “fast” scans, and can now use that neural network as part of the connectomics process.