
Airbnb's Architecture
Hey,
Today we’ll be talking about
Airbnb’s Architecture - Jessica Tai is an engineering manager at Airbnb and she recently gave a fantastic talk on how Airbnb’s architecture has evolved over the years.
Airbnb’s start as a Ruby on Rails monolith and the issues that arose during hypergrowth
Airbnb’s shift to microservices and issues engineers faced with collaboration
The migration to Micro and Macroservices and potential challenges
Plus some tech snippets on
How Slack uses Kafka
Antipatterns you should avoid with pair programming
An introduction to GPUs with OpenGL
Questions? Please contact me at arpan@quastor.org.
Quastor is a free Software Engineering newsletter that sends out summaries of technical blog posts, deep dives on interesting tech and FAANG interview questions and solutions.
Airbnb’s Architecture
Jessica Tai is an engineering manager at Airbnb where she works on platform infrastructure. She gave a great talk at QCon on Airbnb’s architecture and how it’s shifted over the years.
Here’s a summary
Airbnb has been through three major stages in their architecture since the company’s founding.
Airbnb started as a Ruby on Rails monolith, then transitioned to a microservices architecture and has now migrated to a hybrid between micro and macroservices (a macroservice aggregates multiple microservices).
We’ll go through each architecture and talk about the pros/cons and why Airbnb migrated.
Monolith (2008 - 2017)
Airbnb started off with a Ruby on Rails monolith and it worked really well for the company.
Most engineers were full stack and could work on every part of the codebase, executing on end-to-end features by themselves. Features could be completed within a single team, which helped the company build new products very quickly.
However, as Airbnb entered hypergrowth, the number of engineers, teams, and lines of code scaled up very quickly.
It became impossible for a single engineer/team to have context on the entire codebase, so ownership and team boundaries were needed.
Airbnb struggled with drawing these team boundaries since the monolith was very tightly coupled. Code changes in one team were having unintended consequences for another team and who owned what was confusing for different parts of the codebase.
There were other scaling pain points like extremely slow deploys, sometimes taking over a day to get a single deploy done.
These issues were leading to a slower developer velocity and Airbnb decided to shift to a microservices oriented approach to reduce these pain points.
Microservices (2017 - 2020)
After learning from their experience with the monolith, Airbnb engineers wanted to be more disciplined with their approach to microservices.
They decided to have 4 different service types
Data fetching service to read and write data
A business logic service able to apply functions and combine different pieces of data together
A workflow service for write orchestration. This handles operations that involve touching pieces of data across multiple services.
A UI aggregation service that puts this all together for the UI
To avoid ownership issues seen with the monolith, each microservice would only have one owning team (and each team could own multiple services).
With these changes, Airbnb also changed the way engineering teams were structured.
Previously, engineering teams were full stack and able to handle anything. But now, with microservices, Airbnb shifted to teams that were just focused on a certain parts of the stack. Some were focused on certain data services while others were focused on specific pieces of business logic.
Airbnb also had a specific team that was tasked with running the migration of monolith to microservice. This team was responsible for building tooling to help with the migration and to teach Airbnb engineers the best practices of microservice building and operations.
After a few years into the microservices migration, new challenges started to arise.
Managing all these services and their dependencies was quite difficult. Teams needed to be more aware of the service ecosystem to understand where any dependencies may lie.
Building an end-to-end feature meant using various services across the stack, so different engineering teams would all need to be involved. All of these teams needed to have similar priorities around that feature, which was difficult to manage as each team owned multiple services.
Micro + Macroservices (2020 - )
To address those collaboration challenges, Airbnb is now instituting a hybrid approach between micro and macroservices. This model focuses on the unification of APIs and on consolidating to make clear places to go for certain pieces of data or functionality.
They’re creating a system where their internal backend service gets its data from the data aggregation service. The data aggregator then communicates with the various service blocks where each service block encapsulates a collection of microservices.
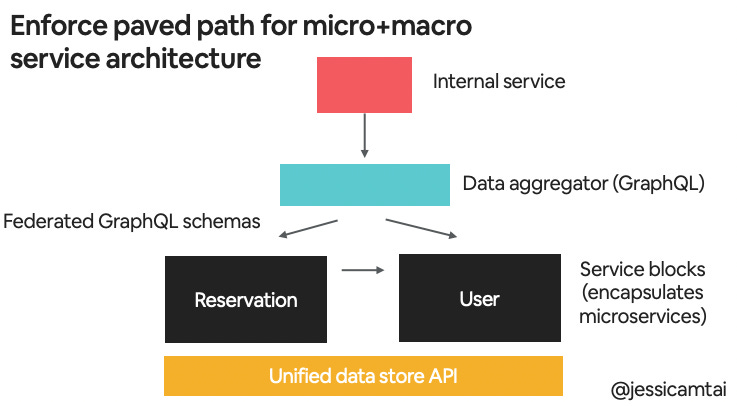
A challenge that Airbnb engineers foresee with this approach is that the data aggregator can become a new monolith. To avoid that, they’re very disciplined about what data/service belongs where.
For the service block layer, engineers need to make sure that they’re defining the schema boundaries in a clean way. There are many pieces of data/logic that can span multiple entities, so it needs to be clearly defined.
For more details, you can watch Jessica’s full talk here.
Quastor is a free Software Engineering newsletter that sends out summaries of technical blog posts, deep dives on interesting tech and FAANG interview questions and solutions.
Tech Snippets
How Slack uses Kafka - This is an awesome blog post from Slack Engineering on how they built and operationalized a Kafka cluster to run at scale.
Slack uses Kafka extensively for their Job Queue and for moving around mission critical data (analytics, logging, billing data and more)
This blog post covers how (and why) Slack automated the operational aspects of managing a Kafka cluster using Chef and Terraform.
You can view their Kafka config on Github.
Pair Programming Antipatterns - Pair Programming can be an excellent tool for educating junior developers on the codebase however there are quite a few anti-patterns you’ll want to avoid. This article gives a great list of some of them for the person leading the pair programming session (the driver) and the person following (the navigator).
Introduction to GPUs with OpenGL - OpenGL is a library that makes it much easier to write code that runs on a GPU and displays graphics. This is a great article that gives an introduction to OpenGL using JavaScript.
Here’s some of our previous tech snippets, in case you missed them
A fantastic series of lectures on Distributed Systems by Robert Morris (co-founder of YCombinator).
The lectures cover actual applications, so there are lectures on ZooKeeper, Google Cloud Spanner, Apache Spark and Bitcoin!
This is an awesome free textbook that introduces you to design patterns. It’s very practical and gives real-world examples of each design pattern (in Java).
The book goes through the Strategy Pattern, Decatur Pattern, Factory Pattern, Observer Pattern and the Singleton Pattern.
It talks about why you would use each pattern, implementations, and potential pitfalls.
Competitive Programmer's Handbook - This is an awesome free textbook that goes through all the major concepts and patterns you need to know for competitive programming. It’s also extremely helpful for coding interviews!
Quastor is a free Software Engineering newsletter that sends out summaries of technical blog posts, deep dives on interesting tech and FAANG interview questions and solutions.
Interview Question
You are given two sorted arrays that can have different sizes.
Return the median of the two sorted arrays.
Here’s the question in Leetcode.
Previous Solution
As a reminder, here’s our last question
Build a class MyQueue that implements a queue using two stacks.
Your class should implement the functions push, pop, peek, and empty.
Here’s the question in LeetCode
Solution
A stack works based on the LIFO principle - last in, first out.
If you push 10 numbers into a stack and then pop out all 10 numbers, you’ll get all 10 numbers back in reverse order.
On the other hand, a queue works based on FIFO - first in, first out.
If you push 10 numbers into a queue and then pop out all 10 numbers, you’ll get all 10 numbers back in the same order.
So, given that we have two stacks, one way of implementing this is to push every element through both stacks.
This will reverse the order twice, which means we’ll get our items back in the same order they were put in (first in, first out).
One stack will be named first, and the other will be named second.
For the push method, we’ll push our items on to the first stack.
Then, when we pop, we’ll first pop everything off the first stack and push it onto the second stack (this is done with our _load function).
After doing that, we can pop an item off our second stack and return it to the user.
Here’s the Python 3 code.

Quastor is a free Software Engineering newsletter that sends out summaries of technical blog posts, deep dives on interesting tech and FAANG interview questions and solutions.
Here’s our last tech summary in case you missed it!
Language Implementations Explained
Bob Nystrom is a software engineer at Google, where he works on the Dart Programming language.
He wrote an amazing book called Crafting Interpreters, where he walks you through how programming language implementations work. In the book, you’ll build two interpreters, one in Java and another in C.
He published the entire book for free here, but I’d highly suggest you support the author if you have the means to do so.
His section on A Map of the Territory gives a fantastic introduction to programming language implementations, so here’s a summary of that section (with my own commentary added in).
Languages vs. Language Implementations
First of all, it’s important to note that a programming language implementation is different from a programming language.
The programming language refers to the syntax, keywords, etc. The programming language itself is usually designed by a committee and there are some standard documents that describe the language. These documents are usually called the Programming Language Specification.
(Not all languages have a specification. Python, for example, has the Python Language Reference, which is the closest thing to it’s specification.)
The language implementation is the actual software that allows you to run code from that programming language. Typically, an implementation consists of a compiler/interpreter.
A programming language can have many different language implementations, and these implementations can all be quite different from each other. The key factor is that all these implementations must be able to run code that is defined according to the programming language specification.
The most popular implementation for Python is CPython but there’s also PyPy (JIT compiler), Jython (Python running on the JVM), IronPython (Python running on .NET) and many more implementations.
The Architecture of a Language Implementation

Language implementations are obviously built differently, but there are some general patterns.
A language implementation can be subdivided into the following parts
Front end - takes in your source code and turns it into an intermediate representation.
Middle end - takes the intermediate representation and applies optimizations to it.
Back end - takes the optimized intermediate representation and turns it into machine code or bytecode.
The intermediate representation is a data structure or code that makes the compiler more modular. It allows you to reuse your front end for multiple target platforms and reuse your backend for multiple source languages.
For example, you can write multiple back ends that turn the intermediate representation into machine code for x86, ARM, and other platforms and then reuse the same front end that turns your C code into intermediate representation.
LLVM is designed around a high-level assembly language that is named “intermediate representation” (here’s the language reference for LLVM IR) while CPython uses a data structure called the Control Flow Graph.

We’ll break down all of these concepts further…
Front end
As we said before, the front end is responsible for taking in your source code and turning it into an intermediate representation.
The first part is scanning (also known as lexical analysis). This is where the front end reads your source code and converts it into a series of tokens. A token is a single element of a programming language. It can be a single character, like a {, or it can be a word, like System.out.println.
After scanning and converting your source code into tokens, the next step is parsing.
A parser will take in the flat sequence of tokens and build a tree structure based on the programming language’s grammar.
This tree is usually called an abstract syntax tree (AST). While the parser is creating the abstract syntax tree, it will let you know if there are any syntax errors in your code.
The front end will also handle tasks like binding. This is where every identifier (variable, etc.) gets linked to where it’s defined.
If the language is statically typed, this is where type checking happens and type errors are reported.
In terms of storing this information, language implementations will do this differently.
Some will store it on the abstract syntax tree as attributes. Others will store it in a lookup table called a symbol table.
All this information will be stored in some type of intermediate representation.
There are a couple of well established styles of intermediate representation out there. Examples include
Having a shared intermediate representation helps make your compiler design much more modular.
Middle End
The middle end is responsible for performing various optimizations on the intermediate representation.
These optimizations are independent of the platform that’s being targeted, therefore they’ll speed up your code regardless of what the backend does.
An example of an optimization is constant folding: if some expression always evaluates to the exact same value, then do that evaluation at compile time and replace the code for the expression with the result.
So, replace

With the result of that expression.

Other examples are removal of unreachable code (reachability analysis) and code that does not affect the program results (dead code elimination).
Back End
The back end is responsible for taking the optimized intermediate representation from the middle end and generating the machine code for the specific CPU architecture of the computer (or generating bytecode).
The back end may perform more analysis, transformations and optimizations that are specific for that CPU architecture.
If the back end produces bytecode, then you’ll also need another compiler for each target architecture that turns that bytecode into machine code.
Or, many runtimes rely on a virtual machine, where a program emulates a hypothetical chip. The bytecode is run on that virtual machine.
An example is the Java Virtual Machine, which runs Java bytecode. You can reuse that backend and write frontends to handle different languages. Python, Kotlin, Clojure and Scala are a few examples of languages that have front ends that can convert that language into Java bytecode.
Quastor is a free Software Engineering newsletter that sends out summaries of technical blog posts, deep dives on interesting tech and FAANG interview questions and solutions.