
An Introduction to Big Data Architectures
How modern big data systems work. Plus, how Slack created an analytics logging library, MIT's awesome class on distributed systems, how to build a functional language and how HTTPS works.
Hey Everyone,
Today we’ll be talking about
An Introduction to Big Data Architectures
What is “big data” and the different types of workloads a big data architecture has to solve for
The components of a big data architecture (data lakes, data warehouses, stream processing, etc.)
The Lambda and Kappa Architectures
Plus, a couple awesome tech snippets on
How Slack created a ReactJS analytics logging library
Robert Morris’ (co-founder of YCombinator) lectures on distributed systems
How to build a functional programming language
How HTTPS works ( a great series of comics that explain HTTPS)
We also have a solution to our last coding interview question, plus a new question from Facebook.

If you find Quastor useful, you should check out Pointer.io!
It’s a reading club for software developers that sends out super high quality engineering-related content.
It’s read by current and future CTOs, senior engineers, so you should definitely sign up if you want to go down that path in the future.
It’s completely free!
sponsored
An Introduction to Big Data Architectures
Microsoft has a great introduction to Big Data Architectures in their Azure docs.
Here’s a summary.
When you’re dealing with massive amounts of data (hundreds of terabytes or petabytes), then the traditional ways of dealing with data start to break down.
You’ll need to use a distributed system, and you’ll have to orchestrate the different components to suit your workload.
Typically, big data solutions involve one or more of the following types of workloads.
Batch processing of data in storage
Real-time processing of data from a stream
Interactive exploration of data
Predictive analytics and machine learning
Components of a Big Data Architecture

Most big data architectures include some or all of the following components
Data Sources - It’s pretty dumb to build a distributed system for managing data if you don’t have any data. So, all architectures will have at least one source that’s creating data. This can be a web application, an IoT device, etc.
Data Storage - Data for batch processing operations is typically stored in a distributed file store that can hold high volumes of large files in various formats. This kind of store is often called a data lake.
Batch Processing - Because the data sets are so large, often a big data solution must process data files using long-running batch jobs to filter, aggregate, and prepare the data for analysis. Map Reduce is a very popular way of running these batch jobs on distributed data.
Real-time Message Ingestion - If the solution includes real-time sources, the architecture must include a way to capture and store real-time messages for stream processing. This portion of a streaming architecture is often referred to as stream buffering.
Stream Processing - After capturing real-time messages, the solution must process them by filtering, aggregating, and otherwise preparing the data for analysis. Apache Storm is a popular open source technology that can handle this for you.
Analytical Data Store - Many big data solutions prepare data for analysis and then serve the processed data in a structured format that can be queried using analytical tools. This can be done with a relational data warehouse (commonly used for BI solutions) or through NoSQL technology like HBase or Hive.
Orchestration - Big data solutions consist of repeated data processing operations that transform source data, move data between multiple sources and sinks, load the processed data into an analytical data store, or push the results straight to a report or dashboard. You can use something like Apache Oozie to orchestrate these jobs.
When you’re working with a large data set, analytical queries will often require batch processing. You’ll have to use something like MapReduce.
This means that getting an answer to your query can take hours, as you have to wait for the batch job to finish.
The issue is that this means you won’t get real time results to your queries. You’ll always get an answer that is a few hours old.
This is a problem that comes up frequently with big data architectures.
The ideal scenario is where you can get some results in real time (perhaps with some loss of accuracy) and combine these results with the results from the batch job.
The Lambda Architecture is a solution to this issue.
Lambda Architecture

The Lambda Architecture solves this by creating two paths for data flow: the cold path and the hot path.
The cold path is also known as the batch layer. It stores all of the historical data in raw form and performs batch processing on the data.
The raw data in the batch layer is immutable. The incoming data is always appended to the existing data, and the previous data is never overwritten.
The cold path has a high latency when answering analytical queries. This is because the batch layer aims at perfect accuracy by processing all available data when generating views.
The hot path is also known as the speed layer, and it analyzes the incoming data in real time. The speed layer’s views may not be as accurate or complete as the batch layer, but they’re available almost immediately after the data is received.
The speed layer is responsible for filling the gap caused by the batch layer’s lag and provides views for the most recent data.
The hot and cold paths converge at the serving layer. The serving layer indexes the batch view for efficient querying and incorporates incremental updates from the speed layer based on the most recent data.
With this solution, you can run analytical queries on your datasets and get up-to-date answers.
A drawback to the lambda architecture is the complexity. Processing logic appears in two different places (the hot and cold paths) and they use different frameworks.
The Kappa Architecture is meant to be a solution to this, where all your data flows through a single path, using a stream processing engine.
You can read more about the Kappa Architecture here.
If you find Quastor useful, you should check out Pointer.io!
It’s a reading club for software developers that sends out super high quality engineering-related content.
It’s read by current and future CTOs, senior engineers, so you should definitely sign up if you want to go down that path in the future.
It’s completely free!
sponsored
Tech Snippets
Slack wrote an interesting blog post on creating a React Analytics Logging Library. Slack’s desktop application is written in ReactJS. The application logs how users interact with it to keep track of what screens users view and what buttons they click. The blog post is on how Slack built the library that handles this. Part 2 of the post is here.
A fantastic series of lectures on Distributed Systems by Robert Morris (co-founder of YCombinator).
The lectures cover actual applications, so there are lectures on ZooKeeper, Google Cloud Spanner, Apache Spark and Bitcoin!
Implementing Functional Languages - This is a free book that will give you a solid understanding of functional programming languages and building compilers for them.
Most of the book is a series of implementations of a small functional language called the Core language.
How HTTPS works - An awesome series of comics that explain how HTTPS works (asymmetric key encryption, TLS handshake, SSL, Certificate Authorities, etc.)
Interview Question
You are given an array of k linked lists.
Each list is sorted in ascending order.
Merge all the linked lists into one sorted linked list and return it.
Here’s the question in LeetCode.
We’ll send the solution in our next email, so make sure you move our emails to primary, so you don’t miss them!
Gmail users—move us to your primary inbox
On your phone? Hit the 3 dots at the top right corner, click "Move to" then "Primary"
On desktop? Back out of this email then drag and drop this email into the "Primary" tab near the top left of your screen
A pop-up will ask you “Do you want to do this for future messages from quastor@substack.com” - please select yes
Apple mail users—tap on our email address at the top of this email (next to "From:" on mobile) and click “Add to VIPs”
Previous Solution
As a reminder, here’s our last question
An image is represented by an m x n integer grid called image where image[i][j] represents the pixel value of the image.
You are given an image grid as well as three integers: sr, sc, and newColor.
You should perform a flood fill on the image starting from the pixel image[sr][sc].
To perform a flood fill, start at the starting pixel and change it’s original color to newColor.
Then, change the color of any pixels connected 4-directionally to the starting pixel that have the same original color of the starting pixel.
After, fill the color of any pixels connected 4-directionally to those pixels that also have the same original color.
Return the modified image after performing the flood fill.
Input: image = [[1,1,1],[1,1,0],[1,0,1]], sr = 1, sc = 1, newColor = 2
Output: [[2,2,2],[2,2,0],[2,0,1]]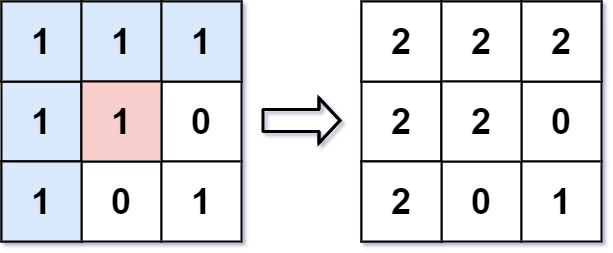
Here’s the question in LeetCode.
Solution
We can solve this question with a Breadth-First Search.
We’ll use a queue (queues can be represented in Python with the deque class from collections)
We’ll start the queue off with the position [sr, sc].
We’ll run a while loop that terminates when our queue is empty.
We pop off an item from our queue in a First-In, First-Out manner (FIFO) by using the popleft function of the deque (pop out an item from the left side of the deque).
We’ll set our matrix’s value at that position to the new color.
Then, we’ll look at that position’s 4 neighbors. If any of the neighbors have a value equal to the original color, then we’ll add that neighbor to our queue.
When our loop terminates, we can return the completed image.
Here’s the Python 3 code.

Quastor Daily is a free Software Engineering newsletter sends out FAANG Interview questions (with detailed solutions), Technical Deep Dives and summaries of Engineering Blog Posts.