Building an in-memory graph database
Hey Everyone,
Today we’ll be talking about
Building an in-memory graph database in JavaScript
This is a summary of a chapter from the amazing, free book 500 Lines or Less that writes useful programs in less than 500 lines and talks about the decisions and tradeoffs being made.
We’ll talk about why Graph databases are useful and a high level overview of how you can build one.
Plus, a couple awesome tech snippets on
A free textbook for Coding Interviews
The State of AI in 2020
How MDN’s autocomplete search works
A Step-By-Step process for turning designs into code.
We also have a solution to our last coding interview question, plus a new question from Microsoft.
Don’t forget to move our emails to primary, so you don’t miss them!
Gmail users—move us to your primary inbox
On your phone? Hit the 3 dots at the top right corner, click "Move to" then "Primary"
On desktop? Back out of this email then drag and drop this email into the "Primary" tab near the top left of your screen
A pop-up will ask you “Do you want to do this for future messages from quastor@substack.com” - please select yes
Apple mail users—tap on our email address at the top of this email (next to "From:" on mobile) and click “Add to VIPs”
Building an in-memory graph database
This is a chapter from 500 Lines or Less that dives into how to build an in-memory graph database in JavaScript.
Summary
Why use a Graph Database?
A Graph is a data structure that is based on a list of vertices and a list of edges. Graphs are a very natural data structure for exploring connections between things.
Let’s say you’re writing a program that tracks an ancestral tree with parents, grandparents, cousins, aunts, etc.
You want to develop a system that allows you to make natural and elegant queries like “Who are Tom’s second cousins?” or “What is Jerry’s connection to the Johnsons?”
In a relationship database, a possible schema would be to have a table of entities (people) and a table of relationships.
A query for Tom’s parents might be

But what if you wanted to extend this to grandparents? Great-grandparents?
You’d have to do a subquery, or use some kind of vendor-specific extension to SQL.
Adding complex relationships like third cousins, great-aunts, etc. will result in a ton of SQL.
Instead, what if you could do something like Tom.mother.mother.children?
Performance
Production graph databases can do graph traversal queries in constant time (with respect to total graph size).
In a non-graph database, asking for a list of someone’s friends can require time proportional to the number of entries, because in the worst-case you have to look at every entry.
Most databases will index over often-queried fields, which turns the O(n) search into a O(log n) search. However, this comes at the cost of write performance and takes up a lot of space (indices can vastly increase the size of a database).
Graph databases accomplish constant time by making direct connections between vertices and edges, so graph traversals are just pointer jumps. Finding a list of someone’s friends takes the same time regardless of the total number of people in the graph, with no additional space cost or write time cost. (Read the full chapter for more details)
However, one downside is that the pointers work best when the whole graph is in memory on the same machine. Sharding a graph database across multiple machines effectively is an active area of research.
Graph Database Implementation
There are two parts to the system: the part that holds the graph and the part that answers questions about the graph.
The first part consists of a JavaScript object (an unordered set of key/value pairs) that represents the graph.
The core of the object is two arrays, one for the edges and one for the vertices. On top of that, it has functions to add vertices and edges to the arrays.
Vertices are objects that have _id, _in, _out properties where _in and _out are lists of the inbound and outbound edges.
The second part, answering queries about the graph, is quite a bit more complicated.
As we stated earlier, we’d like to answer queries like Tom.mother.mother.children.
This could be represented in our graph as
graph.vertices(“Tom”).out(“mother”).out(“mother”).in(“children”)
The mental model for evaluation is
Request a set of vertices
Pass the returned set as input to a pipe
Repeat as necessary
The core of the query interpreter is a function called a pipetype, where each pipetype will represent one query method in the method chain.
So, for graph.vertices(“Tom”).out(“mother”).out(“mother”), there would be pipetypes for each of the out(“mother”) method calls.
The graph database then uses an object called a gremlin to traverse through the graph. Gremlins have a current vertex and some local state.
Pipetypes will take in a gremlin as a parameter and then return more gremlins (depending on the query the pipetype represents). This process is managed by the query interpreter.
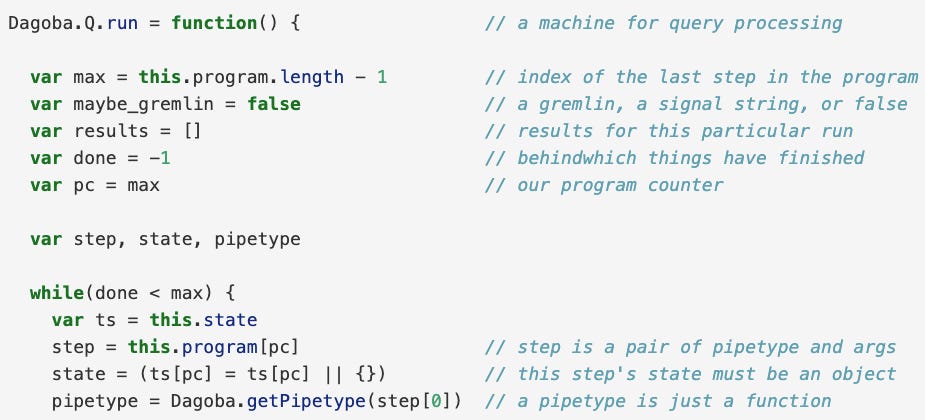
The chapter then builds on top of this to efficiently add functionality like
Filtering results based off certain criteria (height or weight for ex.)
Taking only a few results from the query
Conditional queries
Read the full chapter for all the details.
Tech Snippets
Competitive Programmer's Handbook - This is an awesome free textbook that goes through all the major concepts and patterns you need to know for competitive programming. It’s also extremely helpful for coding interviews!
State Of AI 2020 - This is a curated list of 2020’s breakthroughs in AI & Data Science. It also links to in-depth articles & videos that explain the linked papers and code.
Here are a couple of the papers that are linked...
DeepFaceDrawing: Deep Generation of Face Images from Sketches - Generate high-quality face images from rough or incomplete sketches using this image-to-image translation technique.
Unsupervised Translation of Programming Languages - A model that converts code from one programming language to another without any supervision. For example, it can take a Python function and translate it to C++.
GPT-3: Language Models are Few-Shot Learners - OpenAI’s GPT-3, a language model with the goal of performing well in any task if it’s given a few examples (few shot).
Learning Joint Spatial-Temporal Transformations for Video Inpainting - A technique for solving the video inpainting problem (completing missing regions in the video frame for a given video), It can reconstruct the entire video with more accuracy and less blurriness than previous SOTA approaches.
How MDN's autocomplete search works (August 2021) - MDN Web Docs is the go-to resource for any front-end engineer when they’re looking up HTML/CSS/JavaScript documentation. They recently added an autocomplete search feature to the website and this accompanying blog post dives into the implementation details.
By the way, MDN web docs is open source, so you can see their actual implementation of autocomplete on their github repo.
A Step-By-Step Process for Turning Designs Into Code - A great article on how to think about frontend development. This article gives a great framework for turning your design files into HTML/CSS/JS. Break down the website’s design into several buckets (layout-level patterns, element-level patterns, color palette, structural ideas) and use these patterns to influence how you build the site.
Interview Question
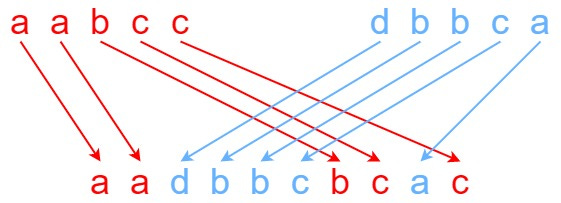
You are given 3 strings: s1, s2 and s3.
Find whether s3 is formed by an interleaving of s1 and s2.
s3 is an interleaving of s1 and s2 if it contains all the characters of s1 and s2 (and only the characters from s1 and s2) and the order of all the characters in the individual strings is preserved.
Input: s1 = “aabcc”, s2 = “dbbca”, s3 = “aadbbcbcac”
Output: True
We’ll send the solution in our next email, so make sure you move our emails to primary, so you don’t miss them!
Gmail users—move us to your primary inbox
On your phone? Hit the 3 dots at the top right corner, click "Move to" then "Primary"
On desktop? Back out of this email then drag and drop this email into the "Primary" tab near the top left of your screen
A pop-up will ask you “Do you want to do this for future messages from quastor@substack.com” - please select yes
Apple mail users—tap on our email address at the top of this email (next to "From:" on mobile) and click “Add to VIPs”
Previous Solution
As a reminder, here’s our last question
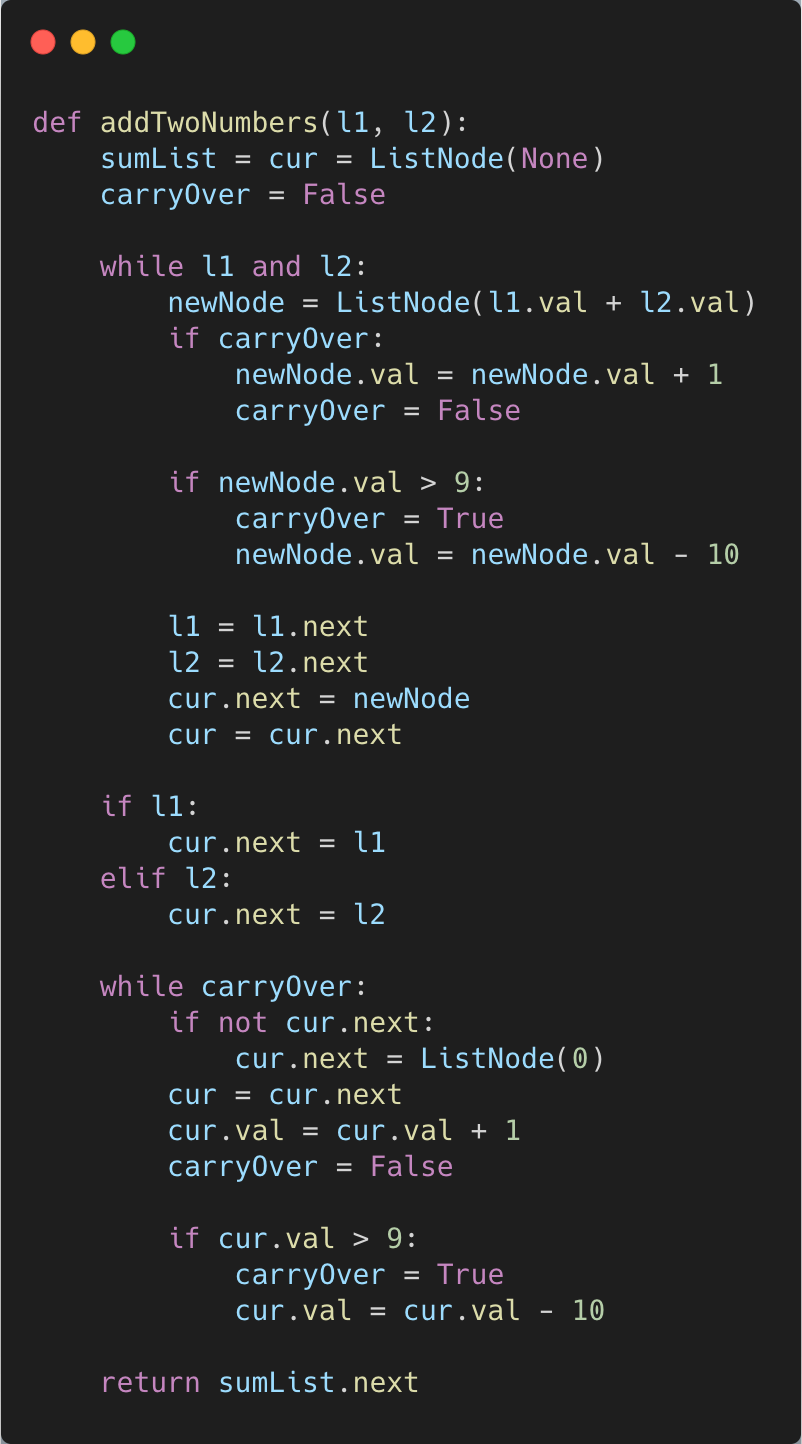
You are given two non-empty linked lists representing two non-negative integers.
The digits are stored in reverse order, and each of their nodes contains a single digit.
Add the two numbers together and return the sum as a linked list.
You may assume the two numbers do not contain any leading zeros.
Example
Input: list1 = 2 -> 4 -> 3, list2 = 5 -> 6 -> 4
Output: 7 -> 0 -> 8
Explanation: 342 + 465 = 807
Here’s the question in LeetCode.
Solution
We can solve this question by iterating through both linked lists simultaneously.
As we iterate through them both, we create a new linked list that represents the sum.
We’ll sum up the value of both linked lists and that value will be the value for our new linked list.
Since each node represents a digit, we’ll have to handle carry overs.
If the sum of the values of both linked lists is greater than 9, then we’ll subtract 10 and set a carry over flag to True.
Then, on the next pair of nodes, we’ll add 1 to the sum to account for the carry over.
After our first loop (which terminates when either one of the linked lists ends), we’ll check if there are any nodes left in either of the linked lists.
If one of the linked lists still has nodes left, then we can just set the new linked list’s next pointer to the rest of the nodes in the remaining linked list.
If our carry over flag is still true, then we’ll continue iterating through the rest of the linked list adding 1.
If we run out of nodes and the carry over flag is true, then we can just add a new node with a value of 1.
When we’re finished, we can return the linked list.
Here’s the Python 3 code.