
How Benchling changed their Search Architecture
Hey Everyone!
First off, I’m changing email platforms and moving Quastor off Substack to another email newsletter service.
To continue getting our emails, please resubscribe here.
Thank you!
Today we’ll be talking about
The Evolution of Benchling’s Search Architecture
Using Postgres and Elasticsearch and how Benchling keeps them synced
Write amplification issues caused by denormalizing data in Elasticsearch
Benchling’s current system and how they reduced the write amplification issues while ensuring fast reads.
Tech Snippets
A collection of Post-Mortems published by companies on why their systems went down.
Building an Interpreter in Rust
How Relational Databases work
Resources on Chaos Engineering
The Evolution of Benchling’s Search Architecture
Benchling is a cloud platform for biotech research & development. Scientists can use the platform to keep track of their experiments, collaborate with other teams, and analyze experiment data.
Over 200,000 researchers use Benchling as a core part of their workflow when running experiments.
Matt Fox is a software engineer at Benchling and he wrote a great blog post on the architecture of their Search System.
Here’s a summary
Benchling’s search feature is a core part of the platform. Researchers can use the search feature to find whatever data they have stored; whether it’s specific experiments, DNA sequences, documents, etc.
The search system also has full-text search capabilities so you can search for certain keywords across all the contents that you’ve stored on Benchling.
Benchling’s Initial Search Architecture (2015 - 2019)
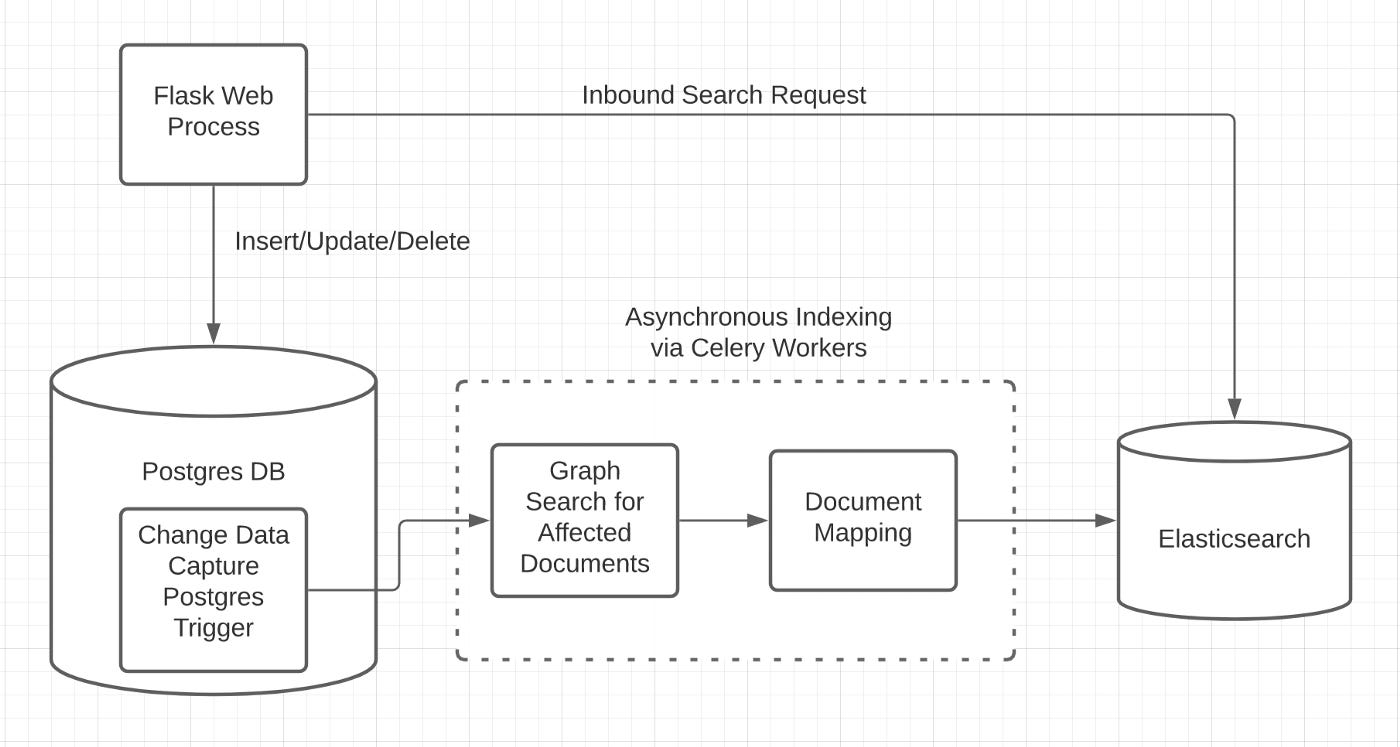
The initial architecture is described in the picture above.
The user would interact with the system through a web server written in Flask.
If the user wanted to perform a CRUD action like creating an experiment or deleting a project, then that would be carried out using the core Postgres database.
If the user wanted to search for something, then that would be done by sending a search request to an Elasticsearch cluster that was kept synced with the Postgres database.
Benchling managed the syncing with a data pipeline that copied any CRUD updates to Postgres over to Elasticsearch.
Whenever the user created/read/updated/deleted something in Postgres, then
Postgres triggers would trigger if a searchable item was changed (items that were not searchable did not need to be stored in Elasticsearch). They would send the changes to a Task Queue (Celery).
Celery Workers would determine all the different documents in Elasticsearch that needed to be updated as a result of the CRUD action. There could be multiple documents that needed to be updated because the data was denormalized when stored in Elasticsearch (we’ll talk about why below).
All the necessary updates would be pushed to Elasticsearch.
This architecture worked well, but had several pain points with the main one being keeping Elasticsearch synced with Postgres. There was too much replication lag.
With the Elasticsearch cluster, fast reads were prioritized (so users could get search results quickly) and data was denormalized when transferred from Postgres.
Denormalization is where you write the same data multiple times in the different documents instead of using a relation between those documents. This way, you can avoid costly joins during reads. Data denormalization improves read performance at the cost of write performance.
The increased cost in write performance is caused by write amplification, where a change to one row in Postgres expands to many document updates in Elasticsearch since you have to individually update all the documents that contain that value.
These costlier writes meant more lag between updating the Postgres database and seeing that update reflected in Elasticsearch. This could be confusing to users as someone might create a new project but then not see it appear if he searches the project name immediately after.
The Benchling team was also dealing with a lot of overhead and complexity with maintaining this search system. They had to maintain both Postgres and Elasticsearch.
Therefore, they decided to move away from Elasticsearch altogether and solely rely on Postgres.
Moving to Postgres (2019 - 2021)
In 2019, the Benchling team migrated to a new architecture for the Search System, that was solely based on Postgres.
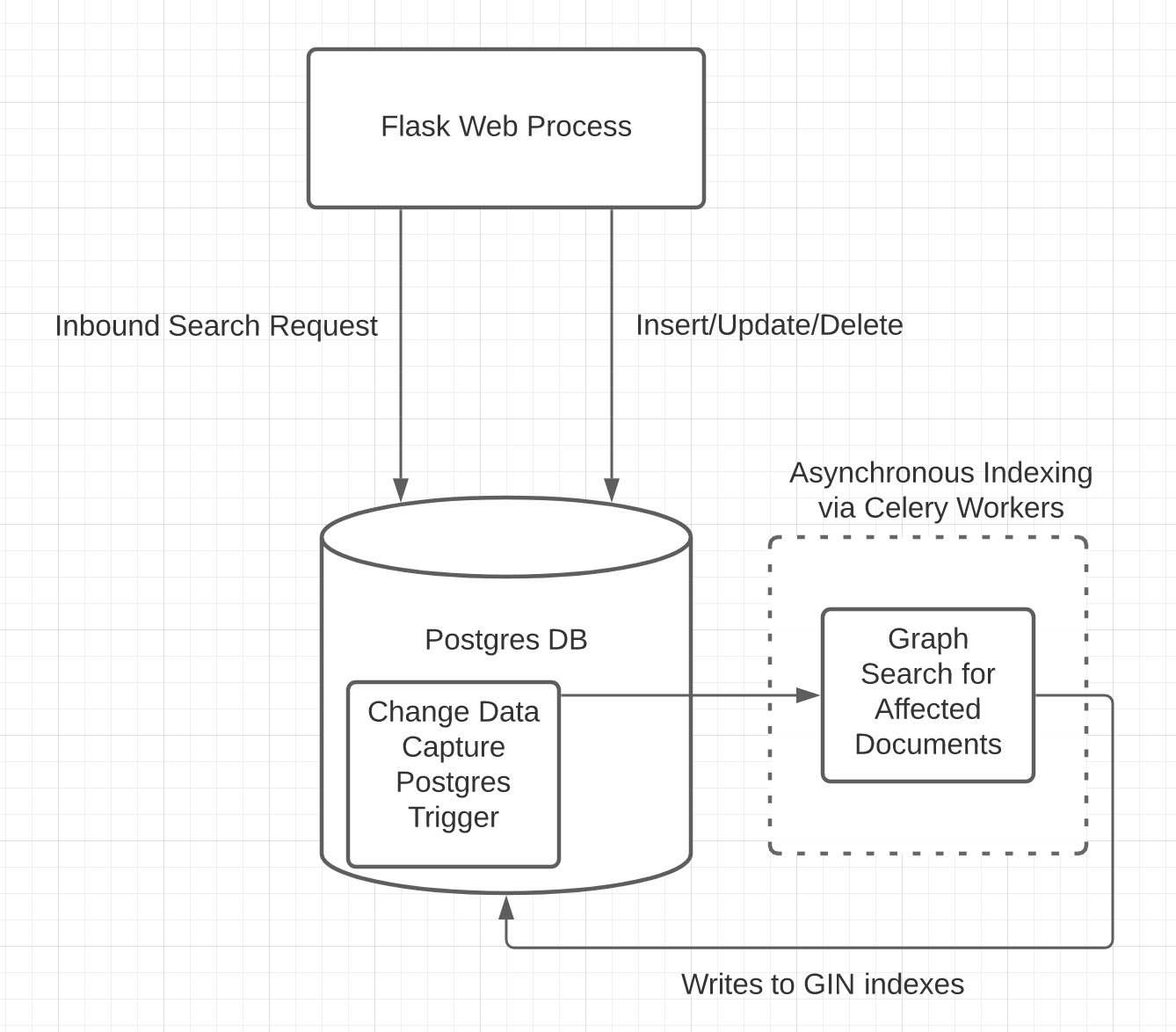
The CRUD system remained the same as before, with Postgres being the core database.
However, searches were done as SQL queries against core tables in Postgres, so they were directly accessing the source of truth (hence no replication lag).
For full-text search queries, they used GIN Indexes, which stands for Generalized Inverted Indexes. An Inverted Index is the most common data structure you’ll use for full text search (Elasticsearch uses an inverted index as well). The basic concept is quite similar to an index section you might find at the back of a textbook where the words in the text are mapped to their location in the textbook.
They used Postgres triggers and Celery to asynchronously update the GIN indexes for full-text search. The replication lag wasn’t much of a problem here because full-text search use cases didn’t typically require strong consistency (real-time syncing). They could rely instead on eventual consistency.
This setup worked great for developer productivity (no need to maintain Elasticsearch) and solved most of the replication lag issues that the team was facing.
However, Benchling experienced tremendous growth during this time period. They onboarded many new customers and users also started to use Benchling as their main data platform.
The sheer volume of data pouring into the system was orders of magnitude greater than they’d seen before.
This caused scaling issues and searches began taking tens of seconds or longer to execute. Searches were done as SQL queries against Postgres, which made heavy use of data normalization. This meant costly joins across many tables when doing a search; hence the slow reads.
Also, the Benchling team faced a lot of difficulty when trying to adapt the system to new use cases.
Building Back on Elasticsearch (2021+)
The third (and current) iteration of Benchling’s search architecture is displayed below.
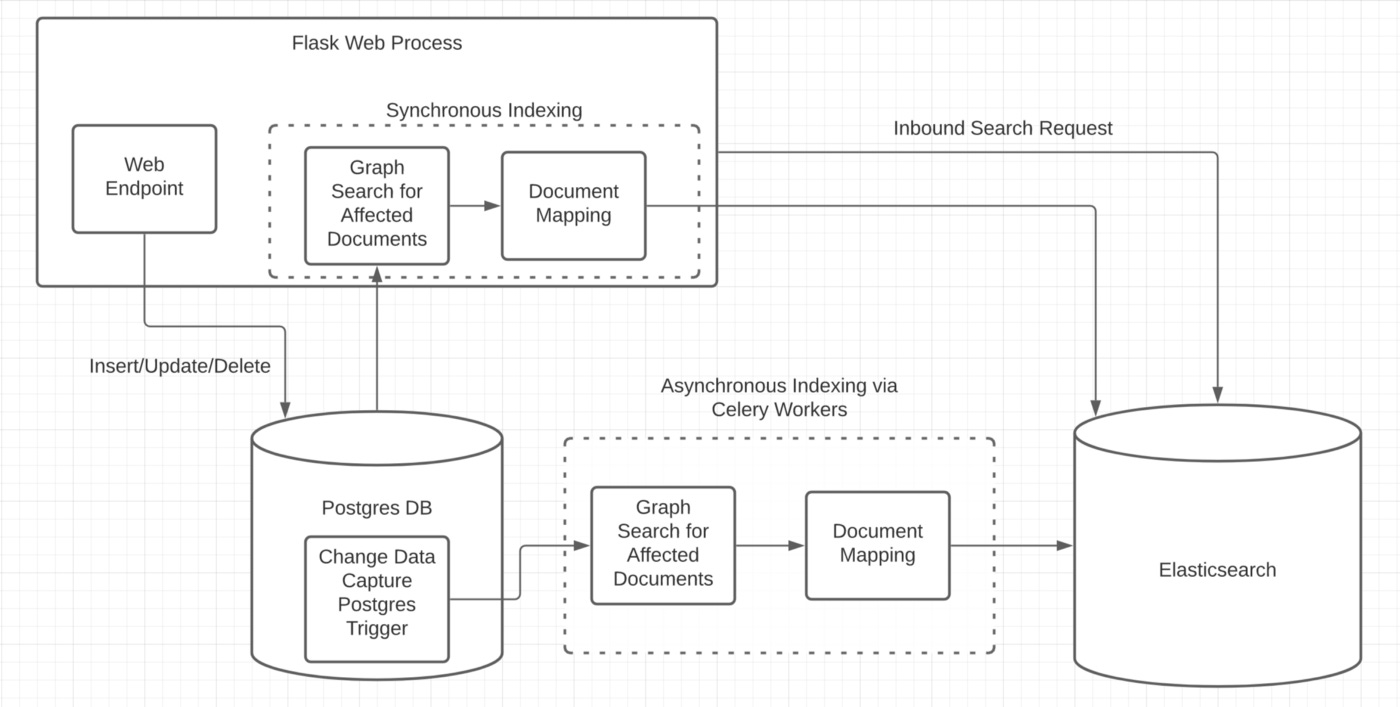
The team evaluated several options for search systems, but they decided to go back to Elasticsearch due to its wide industry adoption, mature plugin and text analysis system, and performant APIs.
They also made some changes to solve some of the issues from the first search system.
The data inconsistency between Postgres and Elasticsearch was the main problem, and that was due to replication lag. Benchling addressed this in the third iteration by adding the option to synchronously index the data into Elasticsearch.
With this, the CRUD actions are first copied into Elasticsearch from Postgres and then the user is given confirmation that the action was successful.
They addressed the write amplification issue (due to the denormalization) by tracking changes at the column level for their Postgres triggers. This greatly reduced the number of false positives that were being re-indexed.
They’ve also done performance testing and made some changes to their Elasticsearch cluster topology so they’re comfortable that the system can handle the load of hundreds of millions of items.
For more details, you can read the full article here.
Tech Snippets
A List of Chaos Engineering Resources - Chaos Engineering is the discipline of building more fault-tolerant distributed systems by introducing some “chaos” into the system (disabling random computers, simulating network outages, etc.)
It was pioneered at Netflix with the Chaos Monkeys tool.
This is a great list of papers, conference talks, blog posts, and more on Chaos Engineering if you’re interested in learning more.
A Collection of Post Mortems - This is a really cool list of post mortem blog posts where companies talk about why their systems went down. Learning from other people’s mistakes is far cheaper than learning from your own, so it’s great to read some of these to understand all the different things that can go wrong.
How Relational Databases work - This is an awesome blog post that gives an overview of the different parts of a relational database. It talks about the core components (to manage processes, memory, the file system, etc.), the Query Manager (checking if a query is valid, optimizing it, executing it, etc.), the Data Manager (managing cache and data on disk) and more.
It gives a great overview of the algorithms that a database uses under the hood.
Building a Language VM - This is an awesome series of blog posts on building an interpreter in Rust. In the series, the author codes a register based VM.
Interview Question
Given two strings word1 and word2, return the minimum number of operations required to convert word1 to word2.
You have the following three operations permitted on a word:
Insert a character
Delete a character
Replace a character
Here’s the question on Leetcode.
Previous Question
As a refresher, here’s the previous question
Given a positive integer n, write a function that computes the number of trailing zeros in n!
Here’s the question in LeetCode.
Solution
This is actually a really interesting question in number theory with a very elegant solution. You can solve it by breaking a number down into its prime factorization.
Brilliant.org has an awesome explanation that gives you an intuition for how this works.
The basic overview is that you break a number down into its prime factorization, count the number of 2s and 5s in the prime factorization.
For every pair of 2s and 5s, that will multiply to a 10 which adds an additional trailing zero to the final product.

The number of 2s in the prime factorization of n! will be more than the number of 5s, so the number of zeros can be determined by counting the number of 5s. All of those 5s can be assumed to match with a 2.
A really cool way of counting the number of 5s in the prime factorization of n! is with a simple summation as illustrated in this theorem.

Read the brilliant article for intuition on how they got that formula.
Here’s the Python 3 code.
