
How LinkedIn scaled Hadoop Distributed File System to store 1 Exabyte of data
Hey Everyone,
Today we’ll be talking about
How to scale HDFS to 1 Exabyte of Data
Replicating the NameNode servers for higher availability
Managing the Java heap size (and ratio) to ensure efficient garbage collection
Ensuring highly-consistent reads from Standby NameNodes to reduce the burden on the Active NameNode
Introduction to the Theory of Computation
An awesome undergraduate-level textbook on the Theory of Computation (it’s free to read).
What is Computational Theory?
An overview of the 3 areas: Complexity Theory, Computability Theory and Automata Theory
Plus, a couple awesome tech snippets on
What Every Programmer Should Know about Memory
A Primer on Design Patterns
We have a solution to our last coding interview question on Linked Lists, plus a new question from Facebook.
Quastor Daily is a free Software Engineering newsletter sends out FAANG Interview questions (with detailed solutions), Technical Deep Dives and summaries of Engineering Blog Posts.
LinkedIn’s journey of scaling HDFS to 1 Exabyte
LinkedIn is the world’s largest professional social networking site with 800 million users from over 200 countries.
In order to run analytics workloads on all the data generated by these users, LinkedIn relies on Hadoop.
More specifically, they store all this data on Hadoop Distributed File System (HDFS).
HDFS was based on Google File System (GFS), and you can read our article on GFS here.
Over the last 5 years, LinkedIn’s analytics infrastructure has grown exponentially, doubling every year in data size and compute workloads.
In 2021, they reached a milestone by storing 1 exabyte of data (1 million terabytes) across all their Hadoop clusters.
The largest Hadoop cluster stores 500 petabytes of data and needs over 10,000 nodes in the cluster. This makes it one of the largest (if not the largest) Hadoop cluster in the industry.
Despite the massive scale, the average latency for RPCs (remote procedure calls) to the cluster is under 10 milliseconds.
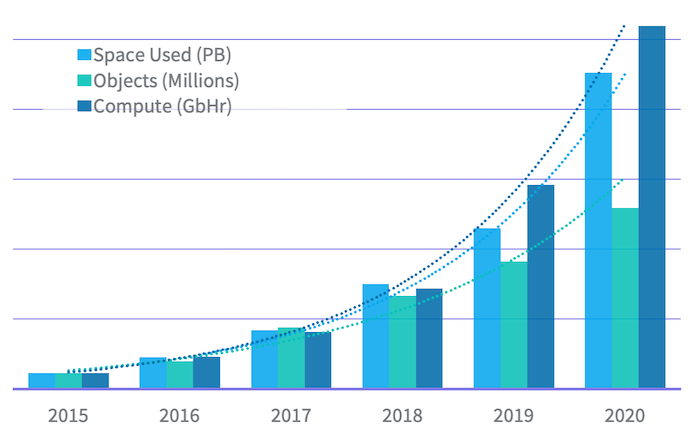
In 2015, the largest Hadoop cluster stored just over 20 petabytes of data.
It took just 5 years for that cluster to grow to over 200 petabytes of data.
In the article, LinkedIn engineers talk about some of the steps they took to ensure that HDFS could scale to 500 terabytes.
Replicating NameNodes
With HDFS, the file system metadata is decoupled from the data.
An HDFS cluster consists of two types of servers: a NameNode server and a bunch of DataNode servers.
The DataNodes are responsible for storing the actual data in HDFS. When clients are reading/writing data to the distributed file system, they are communicating directly with the DataNodes.
The NameNode server keeps track of all the file system metadata like the directory tree, file-block mappings (Hadoop breaks up files into 128 megabyte units called data blocks), which block is stored on which DataNodes, etc.
The NameNode also helps coordinate all the action in HDFS.
A client will first ask NameNode for the location of a certain file. NameNode will respond with the DataNode that contains that file and the client can then read/write their data directly to that DataNode server.

If your NameNode server goes down, then that’s no bueno. Your entire Hadoop cluster will be down as the NameNode is a single point of failure.
Also, when you’re operating at the scale of hundreds of petabytes in your cluster, restarting NameNode can take more than an hour. During this time, all jobs on the cluster must be suspended.
This is a big problem if you have a 500 petabyte cluster.
When you have clusters that large, it becomes extremely expensive to have downtime since a massive amount of processes at the organization rely on that cluster (that cluster accounts for half of all the data at LinkedIn).
Additionally, upgrading the cluster also becomes an issue since you have to restart the NameNode. This results in hours of additional downtime.
Fortunately, Hadoop 2 introduced a High Availability feature to solve this issue. With this feature, you can have multiple replicated NameNode servers.
The way it works is that you have a single Active NameNode that receives all the client’s requests.
The Active NameNode will publish it’s transactions into a Journal Service (LinkedIn uses Quorum Journal Manager for this) and the Standby NameNode servers will consume those transactions and update their namespace state accordingly.
This keeps them up-to-date so they can take over in case the Active NameNode server fails.
LinkedIn uses IP failover to make failovers seamless. Clients communicate to the Active NameNode server using the same Virtual IP address irrespective of which physical NameNode server is assigned as the Active NameNode. A transition between NameNode servers will happen transparently to the clients.
Now, performing rolling updates is also much easier.
First, one of the Standby NameNodes is upgraded with the new software and restarted.
Then, the Active NameNode fails over to the upgraded standby and is subsequently upgraded and restarted.
After, the DataNodes can also be restarted with the new software. The DataNode restarts are done in batches, so that at least one replica of a piece of data remains online at all times.
Java Tuning
Previously, we talked about how the NameNode server will keep track of all the file system metadata.
The NameNode server keeps all of this file system metadata in RAM for low latency access.
As the filesystem grows, the namespace will also grow proportionally.
This adds the requirement for periodic increases of the Java heap size on the NameNode server (Hadoop is written in Java).
LinkedIn’s largest NameNode server is set to use a 380 gigabyte heap to maintain the namespace for 1.1 billion objects.
Maintaining such a large heap requires elaborate tuning in order to provide high performance.
The Java heap is generally divided into two spaces: Young generation and Tenured (Old) generation.
An object will first start in the young generation, and as it survives garbage collection events, it will get promoted to eventually end up in the old generation.
As the workload on the NameNode increases, it generates more temporary objects in the young generation space.
The growth of the namespace increases the old generation.
LinkedIn engineers try to keep the storage ratio between the young and old generations at around 1:4.
By keeping the young and Old spaces appropriately sized, LinkedIn can completely avoid full garbage collection events (where both the Young and Old generations are collected), which would result in a many-minutes-long outage in the NameNode.
Non-Fair Locking
NameNode is a highly multithreaded application and it uses a global read-write lock to control concurrency.
The write lock is exclusive (only one thread can hold it and write) while the read lock is shared, allowing multiple reader threads to run while holding it.
Locks in java support two modes
Fair - Locks are acquired in FIFO order
Non-fair - Locks can be acquired out of order
With fair locking, the NameNode server frequently ends up in situations where writer threads block reader threads (where the readers could be running in parallel).
Non-fair mode, on the other hand, allows reader threads to go ahead of the writers.
This results in a substantial improvement in overall NameNode performance, especially since the workload is substantially skewed towards read requests.
Other Optimizations
Satellite Clusters
HDFS is optimized for maintaining large files and providing high throughput for sequential reads and writes.
As stated before, HDFS splits up files into blocks and then stores the blocks on the various DataNode servers.
Each block is set to a default size of 128 megabytes (LinkedIn has configured their cluster to 512 megabytes).
If lots of small files (the file size is less than the block size) are stored on the HDFS cluster, this can create issues by disproportionately inflating the metadata size compared to the aggregate size of the data.
Since all metadata is stored in the NameNode server’s RAM, this becomes a scalability limit and a performance bottleneck.
In order to ease these limits, LinkedIn created Satellite HDFS Clusters that handled storing these smaller files.
You can read the details on how they split off the data from the main cluster to the satellite clusters in the article.
Consistent Reads from Standby NameNodes
The main limiting factor for HDFS scalability eventually becomes the performance of the NameNode server.
However, LinkedIn is using the High Availability feature, so they have multiple NameNode servers (one in Active mode and the others in Standby state).
This creates an opportunity for reading metadata from Standby NameNodes instead of the Active NameNode.
Then, the Active NameNode can just be responsible for serving write requests for namespace updates.
In order to implement this, LinkedIn details the consistency model they used to ensure highly-consistent reads from the Standby NameNodes.
Read the full details in the article.
Quastor Daily is a free Software Engineering newsletter sends out FAANG Interview questions (with detailed solutions), Technical Deep Dives and summaries of Engineering Blog Posts.
Tech Snippets
This is an awesome free textbook that introduces you to design patterns. It’s very practical and gives real-world examples of each design pattern (in Java).
The book goes through the Strategy Pattern, Decatur Pattern, Factory Pattern, Observer Pattern and the Singleton Pattern.
It talks about why you would use each pattern, implementations, and potential pitfalls.
What Every Programmer Should Know about Memory - This amazing paper goes over…
RAM - Static RAM (SRAM) vs. Dynamic RAM (DRAM), and how RAM works.
CPU Caches - Cache Operation, Implementation, Measurement of Cache Effects
NUMA (Non Uniform Memory Access) systems - NUMA hardware and why it’s useful
How to write code with performs well in various situations
Tools that help you do a better job on memory management
Interview Question
Write a function to randomly generate a set of m integers from an array of size n.
Each element must have an equal probability of being chosen.
We’ll send a detailed solution in our next email, so make sure you move our emails to primary, so you don’t miss them!
Gmail users—move us to your primary inbox
On your phone? Hit the 3 dots at the top right corner, click "Move to" then "Primary"
On desktop? Back out of this email then drag and drop this email into the "Primary" tab near the top left of your screen
Apple mail users—tap on our email address at the top of this email (next to "From:" on mobile) and click “Add to VIPs”
Introduction to the Theory of Computation
This is a fantastic (free) undergraduate-level textbook on the Theory of Computation.
We’ll be giving a (very) brief intro to the Theory of Computation below.
Computational Theory revolves around the question of “What are the fundamental capabilities and limitations of computers?”
The goal is to develop formal mathematical models of computation that are useful frameworks of real-world computers.
An example of a model is the RAM (Random-access Machine) Model of Computation which is useful for computational complexity analysis.
When you’re finding the Big O (worst-case time complexity) of an algorithm, you’re using the RAM model to make assumptions about the runtime of certain operations (assigning a variable is constant time, basic operations are constant time, etc.)
Computational Theory can be split into 3 main areas
Complexity Theory - This area aims to classify computational problems according to their degree of “difficulty”.
A problem is called “easy” if it is efficiently solvable.
An example of an easy problem is to sort a sequence of 1,000,000 numbers.
On the other hand, an example of a hard problem is to factor a 300-digit integer into it’s prime factors. Doing this would take an unattainable amount of computational power.
With complexity theory, you also want to give a rigorous proof that a computational problem that seems hard is actually really hard.
You want to make sure that the problem is hard and not that the problem is actually easy but you’re using an inefficient algorithm.
Computability Theory - This area aims to classify computational problems as being solvable or unsolvable.
This field was started in the 1930s by Kurt Gödel, Alan Turing and Alonzo Church.
As it turns out, there are a great many computational problems that cannot be solved by any computer program. You can view a list of some of these problems here.
Automata Theory - This area deals with the definitions and properties of different types of computational models.
Examples of such models are
Finite Automata - used in text processing, compilers and hardware design.
Context-Free Grammars - used to define programming languages and in AI
Turing Machines - form a simple abstract model of a “real” computer, like the one you’re using right now.
Automata Theory studies the computational problems that can be solved by these models and tries to find whether the models have the same power, or if one model can solve more problems than the other.
The textbook delves into all 3 of these areas so check it out if you’re interested!
Previous Solution
As a reminder, here’s our last question
You are given a doubly-linked list where each node also has a child pointer.
The child pointer may or may not point to a separate doubly linked list.
These child lists may have one or more children of their own, and so on, to produce a multilevel data structure.
Flatten the list so that all the nodes appear in a single-level, doubly linked list.
Here’s the question in LeetCode.
Solution
We can solve this question recursively.
We’ll have a recursive function called _flatten that takes in a linked list and flattens it.
_flatten will then return the head and the tail (last node) of the flattened linked list.
We’ll iterate through our linked list and check if any of the nodes have a child linked list.
If a node does have a child linked list, then we’ll call _flatten on the child linked list.
Then, we’ll insert the flattened linked list inside of our current linked list after the current node.
After inserting it, we can continue iterating through the rest of our linked list checking for child nodes.
Here’s the Python 3 code.
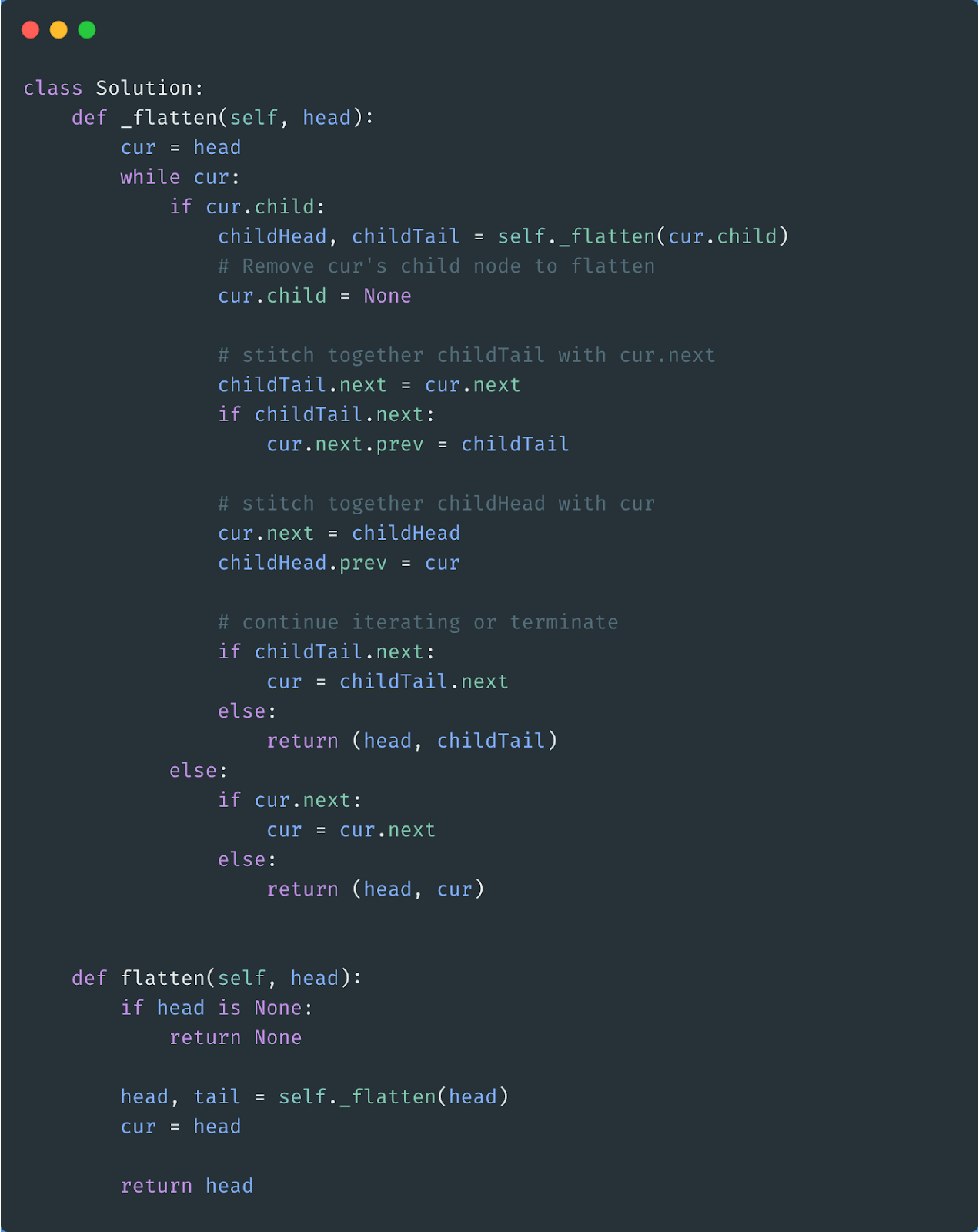
What’s the time and space complexity of the functions in our solution? Reply back with your answer and we’ll tell you if you’re right/wrong.
Quastor Daily is a free Software Engineering newsletter sends out FAANG Interview questions (with detailed solutions), Technical Deep Dives and summaries of Engineering Blog Posts.