


How Lyft stores the data powering their ML models
Hey!
Today we’ll be talking about
How Lyft serves feature data to their ML models
Machine learning forms the backbone of Lyft’s app. The Feature Serving service at Lyft is responsible for serving feature data to these ML models.
How Lyft stores feature definitions and ingests feature data into the service using Flyte and Apache Flink.
How Lyft uses Redis, DynamoDB, Hive and Elasticsearch to serve feature data to all their ML models.
Etsy’s Migration to TypeScript
Etsy’s codebase is structured as a monorepo with tens of thousands of JavaScript files.
Etsy talks about the strategy they took for their migration (gradual migration, strict types, etc.)
The specific tooling Etsy engineers found useful when making the transition
The approach they took to onboard their engineering team (several hundred engineers) to TypeScript
Plus, some tech snippets on
How to write unmaintainable code
Best practices for logging
How to build a second brain as a software engineer
We also have a solution to our last Google interview question and a new question from Microsoft.
Quastor is a free Software Engineering newsletter that sends out summaries of technical blog posts, deep dives on interesting tech and FAANG interview questions and solutions.
Serving Feature Data at Scale
Lyft uses machine learning extensively throughout their app. They use ML models to decide the optimal way to match drivers with riders, figure out the price for a ride, distribute coupons to riders, and a lot more.
In order for the ML models to run, Lyft engineers have to make sure the model’s features are always available.
The features are the input that an ML model uses in order to get its prediction. If you’re building a machine learning algorithm that predicts a house’s sale price, some features might be the number of bedrooms, square footage, zip code, etc.
A core part of Lyft’s Machine Learning Platform is their Feature Serving service, which makes sure that ML models can get low latency access to feature data.
Vinay Kakade worked on Lyft’s Machine Learning Platform and he wrote a great blog post on the architecture of Lyft’s Feature Serving service.
Here’s a summary
Lyft’s ML models are computed in two ways.
Some are computed via batch jobs. Deciding which users should get a 10% off discount can be computed via a batch job that can run nightly.
Others are computed in real time. When a user inputs her destination into the app, the ML model has to immediately output the optimal price for the ride.
Lyft also needs to train their ML models (determine the optimal model parameters to produce the best predictions) which is done via batch jobs.
The Feature Serving service at Lyft is responsible for making sure all features are available for both training ML models and for making predictions in production.
The service hosts several thousand features and serves millions of requests per minute with single-digit millisecond latency. It has 99.99%+ availability.
Here’s the architecture.
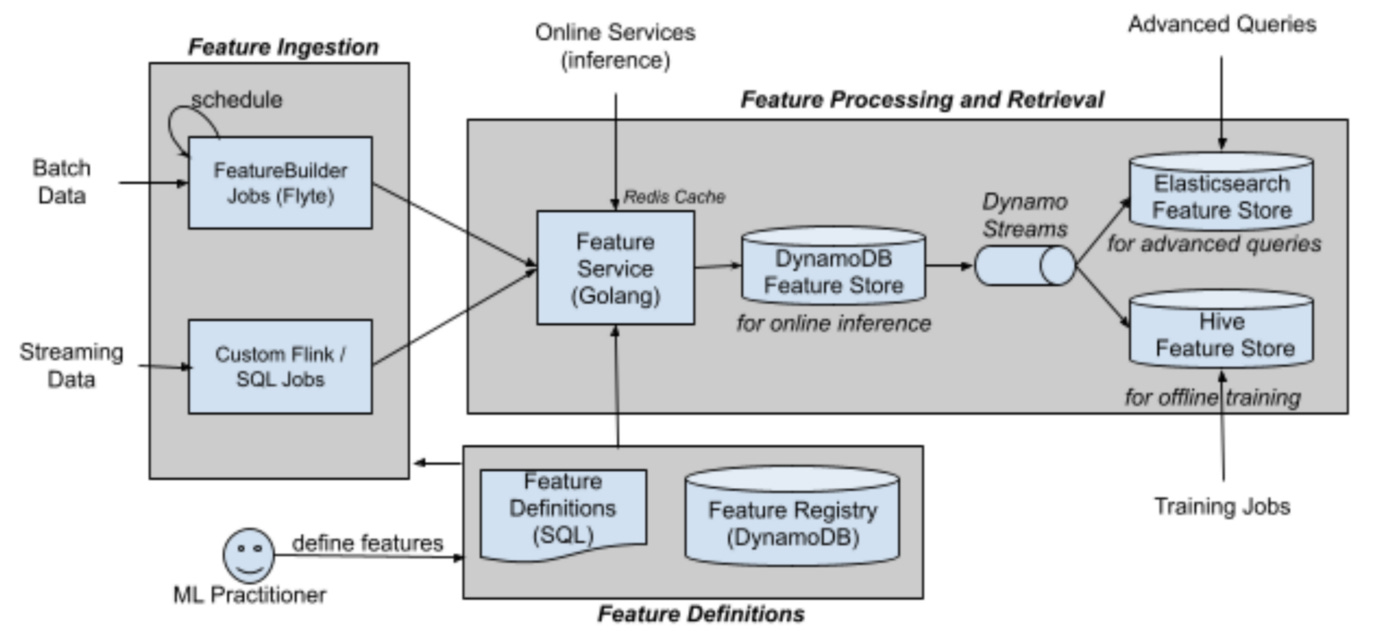
The core parts of the Feature Serving service are the
Feature Definitions
Feature Ingestion
Feature Processing & Retrieval
Feature Definitions
The features are defined in SQL. The complexity of the definitions can range from a single query to thousands of lines of SQL comprising complex joins and transformations.
The definitions also have metadata in JSON that describes the feature version, owner, validation information, and more.
Feature Data Ingestion
For features defined on batch data, Lyft uses Flyte to run regularly scheduled feature extraction jobs. The job executes SQL against Lyft’s data warehouse and then writes to the Feature Service.
For real time feature data, Lyft uses Apache Flink. They execute SQL against a stream window and then write to the Feature Service.
Feature Processing and Retrieval
The Feature Serving service is written in Golang and has gRPC and REST endpoints for writing and reading feature data.
When feature data is added to the service, it is written in both DynamoDB and Redis (Redis is used as a write-through cache to reduce read load on DynamoDB).
Lyft uses Dynamo streams to replicate the feature data to Apache Hive (their data warehouse tool) and Elasticsearch.
The Feature Serving service will then utilize the Redis cache, DynamoDB, Hive and Elasticsearch to serve requests for feature data.
For real-time ML models that need feature data back quickly, the Feature Serving service will try to retrieve the feature data from the Redis cache. If there is a cache miss, then it will retrieve the data from DynamoDB.
For batch-job ML models, they can retrieve the feature data from Hive. If they have an advanced query then they can also use Elasticsearch. You can read more about how Lyft uses Elasticsearch (and performance optimizations they’ve made) here.
For more details on their Feature Serving service, you can read the full article here.
Quastor is a free Software Engineering newsletter that sends out summaries of technical blog posts, deep dives on interesting tech and FAANG interview questions and solutions.
Tech Snippets
How to Write Unmaintainable Code - This is a hilarious set of essays on how you can write the most unmaintainable code possible.
Obviously, the essays are tongue in cheek but they’re a useful collection of anti-patterns that you should avoid.
Topics discussed include how to pick ambiguous variable names, ignore standard libraries and roll your own, testing is for cowards and document how not why.
Best Practices for Logging - If you’re a backend developer, you probably have some type of a logging system in place. Here are some useful tips to make your logs more meaningful.
Separate parameters and messages - A typical log message contains two parts: a handwritten message that explains what was going on, and a list of parameters involved. Separate both!

How to build a second brain as a software engineer - A second brain is a personal knowledge management system (PKM) that you can use to organize your thoughts and references. Two popular ways of doing this are Zettlekasten and The PARA method.
This article goes through how to build your own PKM so you can become a better engineer.

Etsy’s Journey to TypeScript
Salem Hilal is a software engineer on Etsy’s Web Platform team. He wrote a great blog post on the steps Etsy took to adopt TypeScript.
Here’s a summary
Etsy’s codebase is a monorepo with over 17,000 JavaScript files, spanning many iterations of the site.
In order to improve the codebase, Etsy made the decision to adopt TypeScript, a superset of JavaScript with the optional addition of types. This means that any valid JavaScript code is valid TypeScript code, but TypeScript provides additional features on top of JS (the type system).
Based on research at Microsoft, static type systems can heavily reduce the amount of bugs in a codebase. Microsoft researchers found that using TypeScript or Flow could have prevented 15% of the public bugs for JavaScript projects on Github.
Strategies for Adoption
There are countless different strategies for migrating to TypeScript.
For example, Airbnb automated as much of their migration as possible while other companies enable less-strict TypeScript across their projects, and add types to their code over time.
In order to determine their strategy, Etsy had to answer a few questions…
How strict do they want their flavor of TypeScript to be? - TypeScript can be more or less “strict” about checking the types in your codebase. A stricter configuration results in stronger guarantees of program correctness. TypeScript is a superset of JavaScript, so if you wanted you could just rename all your .js files to .ts and still have valid TypeScript, but you would not get strong guarantees of program correctness.
How much of their codebase do they want to migrate? - TypeScript is designed to be easily adopted incrementally in existing JavaScript projects. Again, TypeScript is a superset of JavaScript, so all JavaScript code is valid TypeScript. Many companies opt to gradually incorporate TypeScript to help developers ramp up.
How specific do they want the types they write to be? - How accurately should a type fit the thing it’s describing? For example, let’s say you have a function that takes in the name of an HTML tag. Should the parameter’s type be a string? Or, should you create a map of all the HTML tags and the parameter should be a key in that map (far more specific)?


Based on the previous questions, Etsy’s adoption strategy looked like
Make TypeScript as strict as reasonably possible, and migrate the codebase file-by-file.
Add really good types and really good supporting documentation to all of the utilities, components, and tools that product developers use regularly.
Spend time teaching engineers about TypeScript, and enable TypeScript syntax team by team.
To elaborate more on each of these points…
Gradually Migrate to Strict TypeScript
Etsy wanted to set the compiler parameters for TypeScript to be as strict as possible.
The downside with this is that they would need a lot of type annotations.
They decided to approach the migration incrementally, and first focus on typing actively-developed areas of the site.
Files that had reliable types were given the .ts file extension while files that didn’t kept the .js file extension.
Make sure Utilities and Tools have good TypeScript support
Before engineers started writing TypeScript, Etsy made sure that all of their tooling supported the language and that all of their core libraries had usable, well-defined types.
In terms of tooling, Etsy uses Babel and the plugin babel-preset-typescript that turns TypeScript into JavaScript. This allowed Etsy to continue to use their existing build infrastructure. To check types, they run the TypeScript compiler as part of their test suite.
Etsy makes heavy use of custom ESLint linting rules to maintain code quality.
They used the TypeScript ESLint project to get a handful of TypeScript specific linting rules.
Educate and Onboard Engineers Team by Team
The biggest hurdle to adopting TypeScript was getting everyone to learn TypeScript.
TypeScript works better the more types there are. If engineers aren’t comfortable writing TypeScript code, fully adopting the language becomes an uphill battle.
Etsy has several hundred engineers, and very few of them had TypeScript experience before the migration.
The strategy Etsy used was to onboard teams to TypeScript gradually on a team by team basis.
This had several benefits
Etsy could refine their tooling and educational materials over time. Etsy found a course from ExecuteProgram that was great for teaching the basics of TypeScript in an interactive and effective way. All members of a team would have to complete that course before they onboarded.
No engineer could write TypeScript without their teammates being able to review their code. Individual engineers weren’t allowed to write TypeScript code before the rest of their team was ready.
Engineers had plenty of time to learn TypeScript and factor it into their roadmaps. Teams that were about to start new projects with flexible deadlines were the first to onboard to TypeScript.
Interview Question
You are given the root to a binary search tree.
Find the second largest node in the tree and return it.
Quastor is a free Software Engineering newsletter that sends out summaries of technical blog posts, deep dives on interesting tech and FAANG interview questions and solutions.
Previous Question
As a refresher, here’s the previous question
Write a program to solve a Sudoku puzzle by filling the empty cells.
A sudoku solution must satisfy all of the following rules:
Each of the digits
1-9must occur exactly once in each row.Each of the digits
1-9must occur exactly once in each column.Each of the digits
1-9must occur exactly once in each of the 93x3sub-boxes of the grid.
The '.' character indicates empty cells.
Here’s the question on LeetCode
Solution
This is a classic example of a backtracking question.
Backtracking is an algorithm where you incrementally build up your solution. If you find that your candidate cannot lead to a valid solution, you backtrack back and pick a different path. You can also think of backtracking as a form of Depth-First Search.
With our Sudoku question, we’ll create 3 arrays to keep track of all of our rows, columns, and squares. Remember that a valid Sudoku solution cannot repeat numbers in a single row, column, or square. Our array will represent each row, column, and square as a set. The set will allow us to check if a number is already in a row, column, or square in O(1) time.
Now, we can write our backtracking function. We’ll write a recursive function that takes in the coordinates of a box.
It will incrementally test values from 1 to 9 as possible numbers to place in the box. Our function will start with 1 and check the row, column, and square associated with that box to make sure none of them already contain a 1.
If this check fails, then our function will move on to 2.
Otherwise, if the check succeeds, then we’ll place 1 in that box and update our respective row, column, and square sets by adding 1 to them.
Then, we’ll move on to the next box in our Sudoku puzzle and recursively call our function.
If at any point, we reach a scenario where we cannot place any number from 1 to 9, then our function will return False and the parent caller will backtrack by removing the number that was placed in the square and moving on to the next possible number.
If we reach the end of the board, we can return True and return the final board configuration.

Quastor is a free Software Engineering newsletter that sends out summaries of technical blog posts, deep dives on interesting tech and FAANG interview questions and solutions.