


How to Design Better APIs
Hey,
Today we’ll be talking about
Looking at how Database Storage Engines work
Log Structured vs. Page Oriented
How Log Structured Storage Engines work
Database Indexes and Hash Indexes
How to design better APIs - Ronald Blüthl wrote an awesome blog post with 15 language-agnostic tips on how to design better APIs. We’ll go through a couple here
Use ISO 8601 UTC dates
Version the API
Pagination
Provide a health check endpoint
Plus some tech snippets on
How Netflix tests for performance regressions
How gifs work
How Medium does code review
Questions? Please contact me at arpan@quastor.org.
Quastor is a free Software Engineering newsletter that sends out summaries of technical blog posts, deep dives on interesting tech and FAANG interview questions and solutions.
How to Design Better APIs
Ronald Blüthl wrote a great blog post on how to design better REST APIs with 15 language-agnostic tips.
We’ll go through a couple of the tips here, but check out his post for the entire list.
Use ISO 8601 UTC dates
ISO 8601 is a standard for communicating date and time data. You should use it when dealing with date and time strings in your API.
An example of an ISO 8601 time is
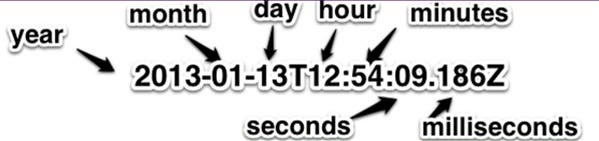
You can remember the format because it is ordered from greatest to smallest in temporal terms.
A year > a month > a day > an hour etc.
Version the API
Version the API and pass the version on each request so that customers aren’t affected later by version changes. Pass the version through HTTP headers or query/path parameters.
You should version the API from the start.
Use Pagination
If an endpoint returns a collection of resources then you should paginate it from the start.
Use a similar pagination format for every single endpoint in your API that has pagination.
Provide a health check endpoint
Provide an endpoint that users can call to check the API service’s health. An example might be GET /health
This endpoint can also be called by other applications like a reverse proxy (load balancer for ex.) to check for service outages.
For the rest of the tips, you can read the full blog post here.
Quastor is a free Software Engineering newsletter that sends out summaries of technical blog posts, deep dives on interesting tech and FAANG interview questions and solutions.
Tech Snippets
Code Reviews at Medium - This is a great blog post that delves into some of the principles that Medium uses when conducting code reviews.
Some of the guidelines are
All changes require at least one approval before getting committed to the codebase.
Make pull requests small and digestible so code reviews can be done quickly. There shouldn’t be too many conceptual changes in a single PR.
PRs should be reviewed within 4 hours (at least one reviewer should respond). If it’s been more than 4 hours, the engineer can add a comment to their pull request that will send a notification to all reviewers requesting feedback.
Add context to the PR so a reviewer can easily understand what the PR is changing and why. If there are any changes that affect the UI, there should be screenshots of the UI that show the change.
How Netflix tests for performance regressions - Before releasing to production, Netflix does significant performance testing for their app. They check responsiveness, latency, start up time, memory usage and more. This blog post provides a detailed look into how Netflix runs these tests and what factors they’re checking.
7 Database paradigms - A great introduction to seven different database paradigms and what they do best
Key-Value databases like Redis
Wide Column databases like Cassandra and HBase
Document Databases like MongoDB
Relational Databases like Postgres and MySQL
Graph Databases like Neo4J
Search Engines like Elasticsearch and Algolia
Multi-model like FaunaDB
A Dive Into Storage Engines
In a previous email, we went over the components of a typical Database Management System (DBMS).
Now, we’re going to dive into the most important component, the storage engine.
This is from Martin Kleppman’s book Designing Data Intensive Applications, so I’d highly recommend you purchase a copy if you’d like to learn more.
The storage engine is responsible for storing, retrieving and managing data in memory and on disk.
A DBMS will often let you pick which storage engine you want to use. For example, MySQL has several choices for the storage engine, including RocksDB and InnoDB.
Having an understanding of how storage engines work is crucial for helping you pick the right database.
The two most popular types of database storage engines are
Log Structured (like Log Structured Merge Trees)
Page Oriented (like B-Trees)
Log Structured storage engines treat the database as an append-only log file where data is sequentially added to the end of the log.
Page Oriented storage engines breaks the database down into fixed-size pages (traditionally 4 KB in size) and they read/write one page at a time.
Each page is identified using an address, which allows one page to refer to another page. These page references are used to construct a tree of pages.
Today, we’ll be focusing on Log Structured storage engines. We’ll look at how to build a basic log structured engine with a hash index for faster reads.
Log Structured Storage Engines
Our storage engine will handle key-value pairs. It’ll have two functions
db_set(key, value) - give the database a (key, value) pair and the database will store it. If the key already exists then the database will just update the value.
db_get(key) - give the database a key and the database will return the associated value. If the key doesn’t exist, then the database will return null.
The storage engine works by maintaining a log of all the (key, value) pairs.
By a log, we mean an append-only sequence of records. The log doesn’t have to be human readable.
Anytime you call db_set, you append the (key, value) pair to the bottom of the log.
This is done regardless of whether the key already existed in the log.
The append-only strategy works well because appending is a sequential write operation, which is generally much faster than random writes on magnetic spinning-disk hard drives (and on solid state drives to some extent).
Now, anytime you call db_get, you look through all the (key, value) pairs in the log and return the last value for any given key.
We return the last value since there may be duplicate values for a specific key (if the key, value pair was inserted multiple times) and the last value that was inserted is the most up-to-date value for the key.
The db_set function runs in O(1) time since appending to a file is very efficient.
On the other hand, db_get runs in O(n) time, since it has to look through the entire log.
This becomes an issue as we scale the log to handle more (key, value) pairs.
But, we can make db_get faster by adding a database index.
The general idea behind an index is to keep additional metadata on the side.
This metadata can act as a “signpost” as the storage engine searches for data and helps it find the data faster.
The database index is an additional structure that is derived from the primary data and adding a database index to our storage engine will not affect the log in any way.
The tradeoff with a database index is that your database reads can get significantly faster. You can use the database index during a read to achieve sublinear read speeds (faster than O(n)).
However, database writes are slower now because for every write you have to update your log and update the database index.
An example of a database index we can add to our storage engine is a hash index.
Hash Indexes
One index we can use is a hash table.
We keep a hash table in-memory where each key in our log is stored as a key in our hash table and the location in the log where that key can be found (the byte offset) is stored as the key’s value in our hash table.

Now, the process for db_set is
Append the (key, value) pair to the end of the log. Note the byte offset for where it’s added.
Check if the key is in the hash table.
If it is, then update it’s value in the hash table to the new byte offset.
If it isn’t, then add (key, byte offset) to the hash table.
One requirement with this strategy is that all your (key, byte offset) pairs have to fit in RAM since the hash map is kept in-memory.
One issue that will eventually come up is that we’ll run out of disk space for our log. Since we’re only appending to our log, we’ll have repeat entries for the same key even though we’re only using the most recent value.
We can solve this issue by breaking our log up into segments.
Whenever our log reaches a certain size, we’ll close it and then make subsequent writes to a new segment file.
Then, we can perform compaction on our old segment, where we throw away duplicate keys in that segment and only keep the most recent update for each key. After removing duplicate keys, we can merge past segments together into larger segments of a fixed size.
We’ll also create new hash tables with (key, byte offset) pairs for all the past merged segments we have and keep those hash tables in-memory.
The merging and compaction of past segments is done in a background thread, so the database can still respond to read/writes while this is going on.
Now, the process for db_get is
Check the current segment’s in-memory hash table for the key.
If it’s there, then use the byte offset to find the value in the segment on disk and return the value.
Otherwise, look through the hash tables for our previous segments to find the key and it’s byte offset.
The methodology we’ve described is very similar to a real world storage engine - Bitcask.
Bitcask is a storage engine used for the Riak database, and it’s written in Erlang. You can read Bitcask’s whitepaper here.
Bitcask (the storage engine that uses this methodology) also stores snapshots of the in-memory hash tables to disk.
This helps out in case of crash recovery, so the database can quickly spin back up if the in-memory hash tables are lost.
This is a brief overview of how a Log Structured database can work.
However, issues that arise are
The hash table of (key, byte offsets) must fit in memory. Maintaining a hashmap on disk is too slow.
Range queries are not efficient. If you want to scan over all the keys that start with the letter a, then you’ll have to look up each key individually in the hash maps.
Quastor is a free Software Engineering newsletter that sends out summaries of technical blog posts, deep dives on interesting tech and FAANG interview questions and solutions.
Interview Question
You are given a function rand5(), which generates a random number between 0 and 4 inclusive (each number is equally likely to be generated).
Use that function to write a rand7() function, that generates a random number between 0 and 6.
Each of the numbers must have an equal probability of being generated.
Quastor is a free Software Engineering newsletter that sends out summaries of technical blog posts, deep dives on interesting tech and FAANG interview questions and solutions.
Previous Solution
As a reminder, here’s our last question
You are given two sorted arrays that can have different sizes.
Return the median of the two sorted arrays.
Here’s the question in Leetcode.
Solution
The brute force way of solving this is to combine both arrays using the merge algorithm from Merge Sort.
After combining both sorted arrays, we can find the median of the combined array.
This algorithm takes linear time.
Here’s the Python 3 code.
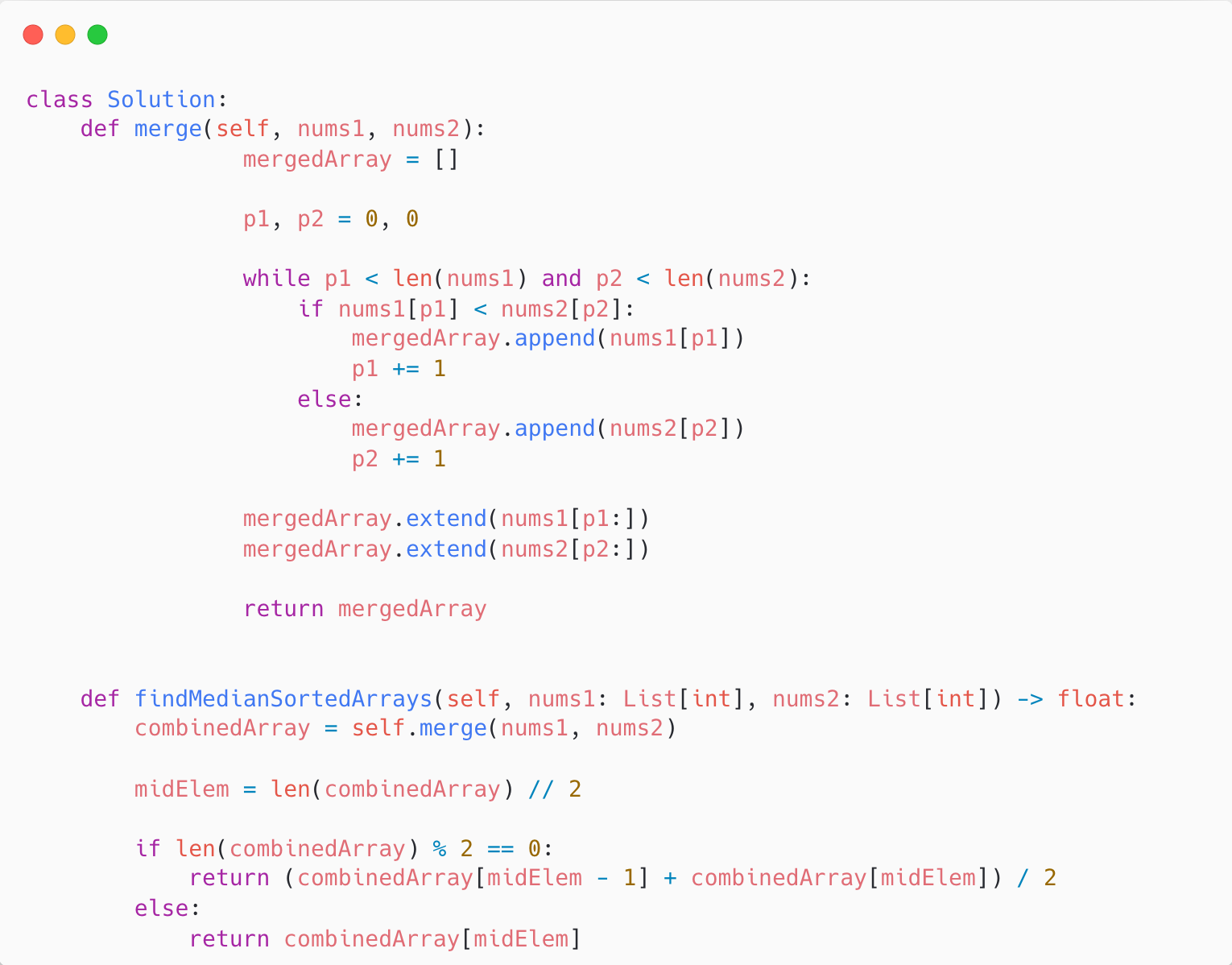
However, can you find the median of the two sorted arrays without having to combine them?
It turns out you can using binary search.
The solution is quite complicated and it’s best understood visually, so I’d highly recommend you watch this video for the explanation (it’s the best explanation I found). It also walks you through the Python 3 code.
Here’s a link to the Python 3 code.
A TLDW is that you can run binary search on the smaller array to select which element you’re going to create your partition from.
Since the median element has to have the same number of elements on the right and left, you can derive the longer array’s partition from the smaller array’s partition.
Then, you check if those two partitions give you the median of the combined array.
If it doesn’t, then you can adjust the partition in the shorter array up or down and reevaluate.
Quastor is a free Software Engineering newsletter that sends out summaries of technical blog posts, deep dives on interesting tech and FAANG interview questions and solutions.