


MapReduce Explained
Hey Everyone,
Today we’ll be talking about
MapReduce
The history behind MapReduce
How you’d use MapReduce
How MapReduce works behind the scenes
Why you should avoid ground-up rewrites
Engineers may be tempted to throw away their codebase and rewrite a new one from scratch out of frustration
This is almost always a terrible idea
Joel Spolsky (co-founder of Stack Overflow) explains why
Plus, a couple awesome tech snippets on
Math for Programmers (covers Calculus, Linear Algebra and Discrete Math)
Why Graph Databases are useful and what kind of data should you use them for
A dive into HTTP/3 (history, core concepts, performance features)
How Grab cut their static JavaScript assets by two-thirds.
We also have a solution to our last coding interview question, plus a new question from Google.
Quastor Daily is a free Software Engineering newsletter sends out FAANG Interview questions (with detailed solutions), Technical Deep Dives and summaries of Engineering Blog Posts.
Map Reduce Explained
History behind Map Reduce
The MapReduce paper was first published in 2004 by Jeff Dean and Sanjay Ghemawat. It was originally designed, built and used by Google.
At the time, Google had an issue. Google’s search engine required constant crawling of the internet, content indexing of every website and analyzing the link structure of the web (for the PageRank algorithm).
This means massive computations on terabytes of data.
Running this scale of computations on a single machine is obviously impossible, so Google bought thousands of machines that could be used by engineers.
For a while, engineers had to laboriously hand-write software to take whatever problem they’re working on and pharm it out to all the computers.
Engineers would have to manage things like parallelization, fault tolerance, data distribution and various other concepts in distributed systems.
If you’re not skilled in distributing systems, then it can be really difficult to do this. If you are skilled in distributed systems, then you can do it but it’s a waste of your time to do it again and again.
Therefore, Google wanted a framework that allowed engineers to focus on the code for their problem (building a web index/link analyzer/whatever) and provided an interface so engineers could use the vast array of machines without having to worry about the distributed systems stuff.
The framework they came up with is MapReduce.
Map and Reduce functions
MapReduce is based on two functions from the Lisp programming language (and many other functional languages): Map and Reduce (also known as Fold).
Map takes in a list of elements (or any iterable object) and a function, applies the function to each element in the list and then returns the list.
Here’s an example of using map to square the numbers in a list.

Reduce takes in a list of elements (or any iterable object), a function and a starting element.
The function (that gets passed into the Reduce operation) takes in a starting element and an element from the list and combines the two in some way. It then returns the combination.
The reduce operation sequentially runs the function on all the elements in the list combining each element with the result from the previous function call.
Here’s an example of using reduce to find the sum of elements in a list.

How MapReduce Works
Example
You have a billion documents and you want to create a dictionary of all the words that appear in those documents and the count of each word (number of times each word appears across the documents).
In order to do this with MapReduce, you have to write a map function and a reduce function.
The map function could look something like this.

EmitIntermediate is a function provided by the MapReduce framework. It’s where you send the output of your map function.
The map function emits each word plus a count of occurrences (here it’s just 1).
The reduce function will then sum together all counts emitted for a particular word.
Here’s the reduce function.

In order to use the MapReduce framework (and take advantage of the distributed computers), you’ll have to provide the map function (listed above), the reduce function (also listed above), names of the input files (for the billion documents), output files (where you want MapReduce to put the finished dictionary) and some tuning parameters (discussed below).
If you’d like to see the full program for this using the MapReduce framework, please look at page 13 of the MapReduce paper.
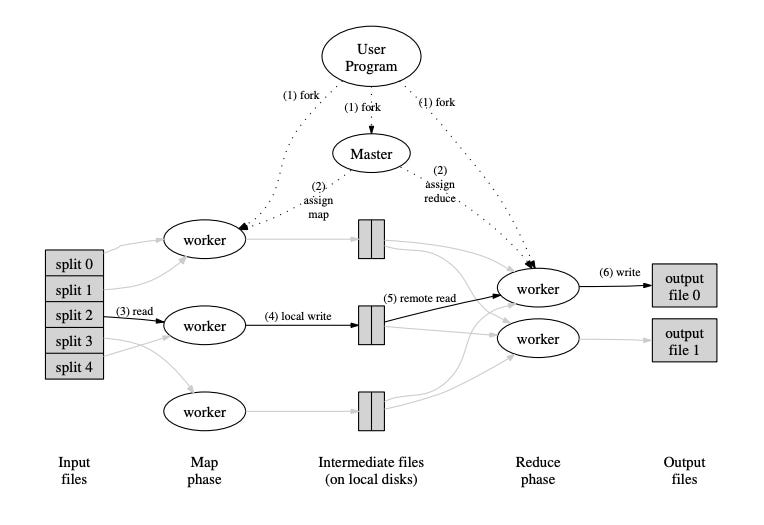
Now, here’s a breakdown of exactly how the MapReduce framework works internally.
The MapReduce library will look at the input files and split them into M pieces (M is a parameter specified by the user).
It will then start up many copies of the MapReduce program on a cluster of machines.
One of the copies will be the master. The rest of the copies are workers that are assigned tasks by the master.
There are M map tasks (for each piece of the input files) and R reduce tasks (R is specified by the user) that the master will assign to the workers. The master will pick idle workers and assign them map or reduce tasks.
A worker who is assigned a map task will read the contents of their input split. They will parse key/value pairs out of the input data and pass each key/value pair to the user-provided Map function.
The Map function will output intermediate key/value pairs.
The intermediate key/value pairs are partitioned into R regions by the partitioning function. The location of these pairs is passed back to the master.
The default partitioning function just uses hashing (e.g. hash(key) mod R) but the user can provide a special partitioning function if desired. For example, the output keys could be URLs and the user wants URLs from the same website to go to the same output file. Then, the user can specify his own partitioning function like hash(Hostname(urlkey)) mod R.
After the location of the intermediate key/value pairs is passed to master, the master assigns reduce tasks to workers and notifies them of the storage locations for their assigned key/value pairs (one of the R partitions).
The reduce worker will read the intermediate key/value pairs from their region and then sort them by the intermediate key so that all occurrences of the same key are grouped together.
The reduce worker then iterates over the sorted intermediate data.
For each unique intermediate key encountered, the reduce worker passes the key and the corresponding set of intermediate values to the user’s Reduce function.
The output of the Reduce function is appended to a final output file for this reduce partition.
After all the map tasks and reduce tasks have been completed, the master wakes up the user program.
The output of the MapReduce execution will be available in R output files, one for each of the Reduce workers.
You can read the full MapReduce paper here.
Quastor Daily is a free Software Engineering newsletter sends out FAANG Interview questions (with detailed solutions), Technical Deep Dives and summaries of Engineering Blog Posts.
Tech Snippets
A Programmer's Introduction to Mathematics - If you’re looking to learn more about areas like machine learning, you might have to brush up on your math background. Jeremy Kun wrote a fantastic textbook on math for programmers that covers topics in Calculus (Single and Multivariable), Linear Algebra, and Discrete Math.
You can set your own price when you purchase the e-book, so you can pay anything from $0 to $100.
Graph Databases Will Change Your Freakin' Life - Most programmers are familiar with Relational databases and non-relational paradigms like Document databases and Key-Value databases. Graph databases are another flavor of the NoSQL paradigm that a lot of engineers aren’t familiar with.
This is a great talk that goes into why Graph Databases are useful and what kind of data you should use them for.
How We Cut GrabFood.com's Page JavaScript Asset Sizes by 3x - GrabFood serves over 175 million requests every week with over 1 terabyte of network egress.
Any reduction in their JavaScript bundle size helps with faster site loads, cost savings for users & Grab, faster build times and more. Grab Engineering was able to do these with several optimizations and cut their static JavaScript assets from 750k to 250 kb.
This blog post delves into how they cut their static asset size by two-thirds.
HTTP/3 from A to Z - After 5 years of development, the new HTTP/3 protocol is nearing its final form. This blog post goes into
HTTP/3 History and core concepts - For people who are new to HTTP/3 and protocols in general. It mainly discusses the basics
HTTP/3 Performance features - performance features in QUIC vs. TCP and how you can look at HTTP/3 as HTTP/2-over-QUIC
HTTP/3 deployment options - The challenges involved in deploying and testing HTTP/3 yourself. It also talks about if and how you should change your web pages and resources.
Why you should avoid ground-up rewrites
One of the oldest pieces of Software Engineering wisdom is to never do a ground up rewrite of your codebase.
Instead, you should favor incremental migration, by moving features into a new system bit-by-bit and diverting live traffic onto the new site as you go.
Joel Spolsky, co-founder of Stack Overflow (CEO from 2010 to 2019) and Glitch, wrote a fantastic blog post on why software engineers are tempted to do ground up rewrites and why it’s a bad idea.
The blog post was written in 2000, but it’s still brought up quite frequently (the programming languages/frameworks may change but the principles remain the same).
Here’s a summary of the blog post.
Oftentimes, programmers will want to throw away their old code and start a rewrite from scratch.
They think the old code is a mess and they’ll give 3 main types of reasons for why:
architectural problems
inefficiency/slow speed
ugly code (bad styling, naming, etc.).
However, the real reason programmers think the old code is a mess is because of a fundamental law of programming - it’s harder to read code than to write it.
It’s easier and more fun to write new code than it is to figure out how old code works. This tricks programmers into thinking that the old codebase is worse than it actually is.
Here are some reasons why you shouldn’t do a ground-up rewrite.
When you start from scratch, there is no reason to believe that you’ll do a better job than you did the first time
The programming team has probably changed since version one, so it doesn’t actually have “more experience”.
Teams will end up making the same mistakes again and also introduce new problems that weren’t in the original version.
You are throwing away a ton of knowledge
Old code has been used. It’s been tested. Lots of bugs have been found and fixed.
When you throw away all that code and start from scratch, you are throwing away all of that knowledge, bug fixes and work.
You are throwing away time
6 months to 1 year of time doing a rewrite can be extremely expensive. That is time where you cannot make strategic changes or react to new features that the market demands, because you don’t have shippable code.
You are wasting time (and money) writing code that already exists.
Read the full blog post for a more in-depth explanation with some examples.
Quastor Daily is a free Software Engineering newsletter sends out FAANG Interview questions (with detailed solutions), Technical Deep Dives and summaries of Engineering Blog Posts.
Interview Question
Given two strings word1 and word2, return the minimum number of steps required to make word1 and word2 the same.
In one step, you can delete exactly one character in either string.
Example 1
Input: word1 = “sea”, word2 = “eat”
Output: 2
We’ll send the solution in our next email, so make sure you move our emails to primary, so you don’t miss them!
Gmail users—move us to your primary inbox
On your phone? Hit the 3 dots at the top right corner, click "Move to" then "Primary"
On desktop? Back out of this email then drag and drop this email into the "Primary" tab near the top left of your screen
A pop-up will ask you “Do you want to do this for future messages from quastor@substack.com” - please select yes
Apple mail users—tap on our email address at the top of this email (next to "From:" on mobile) and click “Add to VIPs”
Previous Solution
As a reminder, here’s our last question
An image is represented by an m x n integer grid called image where image[i][j] represents the pixel value of the image.
You are given an image grid as well as three integers: sr, sc, and newColor.
You should perform a flood fill on the image starting from the pixel image[sr][sc].
To perform a flood fill, start at the starting pixel and change it’s original color to newColor.
Then, change the color of any pixels connected 4-directionally to the starting pixel that have the same original color of the starting pixel.
After, fill the color of any pixels connected 4-directionally to those pixels that also have the same original color.
Return the modified image after performing the flood fill.
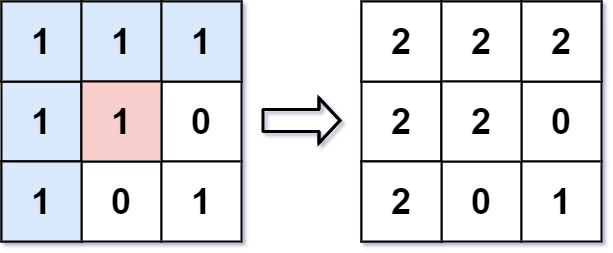
Here’s the question in LeetCode.
Solution
We can solve this question with a Breadth-First Search.
We’ll use a queue (queues can be represented in Python with the deque class from collections)
We’ll start the queue off with the position [sr, sc].
We’ll run a while loop that terminates when our queue is empty.
We pop off an item from our queue in a First-In, First-Out manner (FIFO) by using the popleft function of the deque (pop out an item from the left side of the deque).
We’ll set our matrix’s value at that position to the new color.
Then, we’ll look at that position’s 4 neighbors. If any of the neighbors have a value equal to the original color, then we’ll add that neighbor to our queue.
When our loop terminates, we can return the completed image.
Here’s the Python 3 code.
