


Observability at Twitter
Hey,
Today we’ll be talking about
Observability at Twitter
The design of Twitter’s legacy logging system and issues that it faced
Twitter’s switch to Splunk and the migration process
Pros/Cons of Splunk for logging
How Facebook encodes Videos
Adaptive Bitrate Streaming vs. Progressive Streaming and a brief intro to video encoders
Facebook’s process for encoding videos.
Facebook’s Benefit-Cost Model for determining the priority of an encoding job in their priority queue
Plus some tech snippets on
A Google Engineering Director talks about what makes a great Engineering Manager
A great GitHub repo with resources for CTOs (or aspiring CTOs)
Advanced Linux Programming (an amazing free textbook that dives into things you should know when writing software for Linux)
How to Review Code as a Junior Engineer
Questions? Please contact me at arpan@quastor.org.
Quastor is a free Software Engineering newsletter that sends out summaries of technical blog posts, deep dives on interesting tech and FAANG interview questions and solutions.
Observability at Twitter
Previously, Twitter used a home-grown logging system called Loglens. Engineers had quite a bit of trouble with Loglens, mainly around it’s low ingestion capacity and limited query capabilities.
To fix this, Twitter adopted Splunk for their logging system. After the switch, they’ve been able to ingest 4-5 times more logging data with faster queries.
Kristopher Kirland is a senior Site Reliability Engineer at Twitter and he wrote a great blog post on this migration and some of the challenges involved (published August 2021).
Here’s a summary
The Legacy Logging System
Before Loglens (the legacy centralized logging system), Twitter engineers had great difficulty with browsing through the different log files from their various backend services. This would be super frustrating when engineers were investigating an ongoing incident.
To solve this, they designed Loglens as a centralized logging platform that would ingest logs from all the various services that made up Twitter.
Their goals for this platform were
Ease of onboarding
Low cost
Little time investment from developers for ongoing maintenance and improvements
Log files would be written to local Scribe daemons, forwarded onto Kafka and then ingested into the Loglens indexing system and written to HDFS.
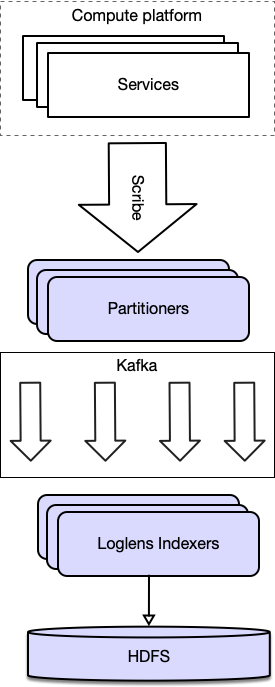
While running Loglens as their logging backend, the platform ingested around 600k events per second per datacenter.
However, only 10% of the logs ingested were actually submitted. The other 90% were discarded by the rate limiter to avoid overwhelming Loglens.
The logging system had very little resource investment (little investment was one of the goals) and that led to a poor developer experience with the platform.
Transitioning to Splunk
Twitter engineers decided to switch to Splunk for their centralized logging platform.
They chose Splunk because it could scale to their needs; ingesting logs from hundreds of thousands of servers in the Twitter fleet. Splunk also offers flexible tooling that satisfies the majority of Twitter’s log analysis needs.
Due to the loosely coupled design of Loglens, migrating to Splunk was pretty straightforward.
Twitter engineers created a new service to subscribe to the Kafka topic that was already in use for Loglens, and then they forwarded those logs to Splunk. The new service is called the Application Log Forwarder (ALF).
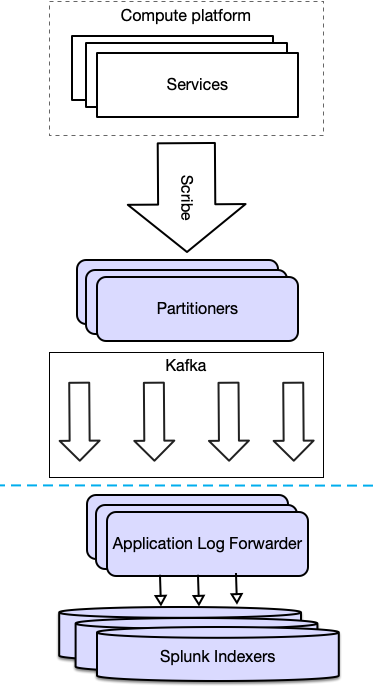
Twitter uses this set up for the majority of their logs (over 85%) but they also use the Splunk Universal Forwarder. With the Universal Forwarder, they just install that application on each server in their fleet and it starts ingesting logs.
With Splunk, Twitter now has a much greater ingestion capacity compared to Loglens. As of August 2021, they collect nearly 42 terabytes of data per datacenter each day. That’s 5 million events per second per datacenter, which is far greater than what Twitter was able to do with Loglens.
They also gained some other features like greater configurability, the ability to save and schedule searches, complex alerting, a more robust and flexible query language, and more.
Challenges of running Splunk
Some of the challenges that Twitter engineers faced with the migration were
Control of flow of data is limited - As stated previously, Twitter uses the Application Log Forwarder (ALF) for 85% of their logging and the Splunk Universal Forwarder for 15% of logging.
If something goes wrong with a service and they start to flood the system with enough logging events to threaten the stability of the Splunk Enterprise Clusters, the ALF can rate limit by log priority or originating service.
However, the Splunk Universal Forwarder lacks the flexibility that the ALF has.
Server maintenance in large clusters is a pain - Server maintenance, like regular reboots, presents a significant challenge. Rebooting too many servers at once can cause interruptions for Splunk searches and poor ingestion rates of new logging data.
Managing Configuration - Twitter uses the typical configuration management tools like Puppet/Chef for the majority of needs, but they fell short of what they wanted for managing indexes and access controls.
They had to create their own service that generated specific configuration files and deployed them to the correct servers.
Modular Inputs are not Resilient - One feature of Splunk is Splunkbase, where you can find a large array of add-ons for all the various products you might be using.
Many add-ons give you the ability to collect data from the API of third-party applications like GitHub, Slack, Jenkins, etc.
However, Twitter engineers found that most of these add-ons are not designed to run in a resilient manner. Instead, they implemented their own plugins to run on their compute infrastructure.
For more information, check out the full blog post here.
Quastor is a free Software Engineering newsletter that sends out summaries of technical blog posts, deep dives on interesting tech and FAANG interview questions and solutions.
Tech Snippets
What Makes a Great Engineering Manager - Dave Rensin is a former Engineering Director at Google. In this interview, he talks about what makes a great EM (engineering manager), how to interview for an EM position and tips for people who are transitioning into EM.
An awesome Github Repo on resources for CTOs (or aspiring CTOs).
The repo contains resources on
Software Development Processes (Scrum/Agile, CI/CD, etc.)
Software Architecture
Product Management
Hiring for technical roles
Advanced Linux Programming - If you’re a developer for the Linux OS, this is a great textbook to teach you advanced topics around how to write programs that work with features like IPC, multiprocessing, multi-threading, and interaction with hardware devices.
The book goes into how you can build applications that are faster and more secure and it also shows peculiarities in the Linux OS including limitations and conventions.
How to Review Code as a Junior Developer - This is an awesome blog post on the Pinterest Engineering blog about how junior developers should do code reviews. Many junior devs may think their feedback (especially when given to developers who are more senior) is a waste of time, but that’s not the case!
Several benefits from reviewing code as a junior developer are
You learn the code base more quickly
You build a feedback circle
You take more ownership over the codebase
How Facebook Encodes Videos
Hundreds of millions of videos are uploaded to Facebook every day.
In order to deliver these videos with high quality and little buffering, Facebook uses a variety of video codecs to compress and decompress videos. They also use Adaptive Bitrate Streaming (ABR).
We’ll first give a bit of background information on what ABR and video codecs are. Then, we’ll talk about the process at Facebook.
Progressive Streaming vs. Adaptive Bitrate Streaming
Progressive Streaming is where a single video file is being streamed over the internet to the client.
The video will automatically expand or contract to fit the screen you are playing it on, but regardless of the device, the video file size will always be the same.

There are numerous issues with progressive streaming.
Quality Issue - Your users will have different screen sizes, so the video will be stretched/pixelated if their screen resolution is different from the video’s resolution.
Buffering - Users who have a poor internet connection will be downloading the same file as users who have a fast internet connection, so they (slow-download users) will experience much more buffering.
Adaptive Bitrate Streaming is where the video provider creates different videos for each of the screen sizes that he wants to target.
He can encode the video into multiple resolutions (480p, 720p, 1080p) so that users with slow internet connections can stream a smaller video file than users with fast internet connections.
The player client can detect the user’s bandwidth and CPU capacity in real time and switch between streaming the different encodings depending on available resources.
You can read more about Adaptive Bitrate Streaming here.
Video Codec
A video codec compresses and decompresses digital video files.
Transmitting uncompressed video data over a network is impractical due to the size (tens to hundreds of gigabytes).
Video codecs solve this problem by compressing video data and encoding it in a format that can later be decoded and played back.
Examples of common codecs include H264 (AVC), MPEG-1, VP9, etc.
The various codecs have different trade-offs between compression efficiency, visual quality, and how much computing power is needed.
More advanced codecs like VP9 provide better compression performance over older codecs like H264, but they also consume more computing power.
You can read more about video codecs here.
Facebook’s Process for Encoding Videos
So, you upload a video of your dog to Facebook. What happens next?
Once the video is uploaded, the first step is to encode the video into multiple resolutions (360p, 480p, 720p, 1080p, etc.)
Next, Facebook’s video encoding system will try to further improve the viewing experience by using advanced codecs such as H264 and VP9.
The encoding job requests are each assigned a priority value, and then put into a priority queue.
A specialized encoding compute pool then handles the job.
Now, the Facebook web app (or mobile app) and Facebook backend can coordinate to stream the highest-quality video file with the least buffering to people who watch your video.
A key question Facebook has to deal with here revolves around how they should assign priority values to jobs?
The goal is to maximize everyone’s video experience by quickly applying more compute-intensive codecs to the videos that are watched the most.
Let’s say Cristiano Ronaldo uploaded a video of his dog at the same time that you uploaded your video.
There’s probably going to be a lot more viewers for Ronaldo’s video compared to yours so Facebook will want to prioritize encoding for Ronaldo’s video (and give those users a better experience).
They’ll also want to use more computationally-expensive codecs (that result in better compression ratios and quality) for Ronaldo.
The Benefit-Cost Model
Facebook’s solution for assigning priorities is the Benefit-Cost model.
It relies on two metrics: Benefit and Cost.
The encoding job’s priority is then calculated by taking Benefit and dividing it by Cost.

Benefit
The benefit metric attempts to quantify how much benefit Facebook users will get from advanced encodings.
It’s calculated by multiplying relative compression efficiency * effective predicted watch time.
The effective predicted watch time is an estimate of the total watch time that a video will be watched in the near future across all of its audience.
Facebook uses a sophisticated ML model to predict the watch time. They talk about how they created the model (and the parameters involved) in the article.
The relative compression efficiency is a measure of how much a user benefits from the codec’s efficiency.
It’s based on a metric called the Minutes of Video at High Quality per GB (MVHQ) which is a measure of how many minutes of high-quality video can you stream per gigabyte of data.
Facebook compares the MVHQ of different encodings to find the relative compression efficiency.
Cost
This is a measure of the amount of logical computing cycles needed to make the encoding family (consisting of all the different resolutions) deliverable.
Some jobs may require more resolutions than others before they’re considered deliverable.
As stated before, Facebook divides Benefit / Cost to get the priority for a video encoding job.
After encoding, Facebook’s backend will store all the various video files and communicate with the frontend to stream the optimal video file for each user.
For more details, read the full article here.
Quastor is a free Software Engineering newsletter that sends out summaries of technical blog posts, deep dives on interesting tech and FAANG interview questions and solutions.
Interview Question
Build a class MyQueue that implements a queue using two stacks.
Your class should implement the functions enqueue, dequeue, and peek.
We’ll send a detailed solution in our next email, so make sure you move our emails to primary, so you don’t miss them!
Gmail users—move us to your primary inbox
On your phone? Hit the 3 dots at the top right corner, click "Move to" then "Primary"
On desktop? Back out of this email then drag and drop this email into the "Primary" tab near the top left of your screen
Apple mail users—tap on our email address at the top of this email (next to "From:" on mobile) and click “Add to VIPs”
Previous Solution
As a reminder, here’s our last question
You are given a dictionary of words.
Write a function that finds the longest word in the dictionary that is made up of other words in the list.
Input: words = ["w","wo","wor","worl","world"]
Output: "world"
Explanation: The word "world" can be built one character at a time by "w", "wo", "wor", and "worl". Here’s the question in LeetCode.
Solution
We can solve this question with a Trie (prefix tree).
The basic idea is we create a Trie with all the words in our dictionary.
Then, we can run a Breadth-First Search on our Trie to find the longest possible word.
We first create a TrieNode class that represents the individual nodes in our Trie.
class TrieNode:
def __init__(self, val = None):
self.val = val
self.children = {}
self.isEnd = NoneThen, we create a Trie class.
The constructor for our Trie class is just initializing our Trie’s root node.
class Trie:
def __init__(self):
self.root = TrieNode()Now, we have to write a function to add words into our Trie.
Here’s the code.
def addWord(self, word):
node = self.root
for l in word:
if l not in node.children:
node.children[l] = TrieNode(l)
node = node.children[l]
node.isEnd = wordWe start at the root node of our Trie.
Then, we go letter by letter in the word we want to add.
We check if the letter is a child in the current node’s children.
If not, we add a new child TrieNode representing our letter.
Then, we can move down to our child letter.
After we’ve inserted all the letters in our word, we mark the last latter’s isEnd variable by changing it to the word itself.
This isEnd variable will be useful for our BFS.
So, now that we have a function to insert words, we can insert all the words in our dictionary inside the Trie.
After we’ve inserted all the words, it’s time to run a BFS on our Trie and find the longest word that is made up of other words in the list.
We’ll start at the root node and look through the root node’s children to find children that are words in our dictionary.
We can tell by looking at the isEnd variable. If the isEnd variable is not None, then that means that the TrieNode represents the end of a word in our dictionary.
So, from our root node we’ll search any child that has an isEnd value.
For each of those nodes, we repeat the process. Search any of that node’s children that has an isEnd value, since those TrieNodes represent the end of words in our dictionary.
On each iteration, we’ll keep track of the longest word we’ve seen by looking at the value of isEnd.
Here’s the code for our BFS.
def _findLongest(self, node):
maxWord = node.isEnd if node.isEnd != None else ""
for l in node.children:
if node.children[l].isEnd != None:
newWord = self._findLongest(node.children[l])
if len(newWord) > len(maxWord):
maxWord = newWord
elif len(newWord) == len(maxWord):
maxWord = min(newWord, maxWord)
return maxWordHere’s the full Python 3 code.

Quastor is a free Software Engineering newsletter that sends out summaries of technical blog posts, deep dives on interesting tech and FAANG interview questions and solutions.