Offline First Applications?
Hey Everyone,
Today we’ll be talking about
Offline-First Web Applications
Offline-first is a software paradigm in response to the trend of moving from desktop apps to web apps
Pros of offline-first apps include better user experience and easier scaling
Cons of offline-first apps include the weak durability guarantees of browser storage and eventual consistency.
Plus, a couple awesome tech snippets on
MIT’s class on the Missing Semester of your CS Education
Real Time Communications Protocols at Scale
A collection of awesome resources for people who want to write programming languages.
We also have a solution to yesterday’s interview question. Plus, a new question from Facebook.
If you’re not signed up for Quastor, be sure to join!
Tech Snippets
The Missing Semester of Your CS Education - An awesome MIT class on the actual tools used by programmers. You can watch the lectures on YouTube here. Topics discussed include
Debugging and Profiling tools
Shell Scripting
Vim
Data Wrangling
Build Systems
Dependency Management
Continuous Integration
and more!
RTC (Real-Time Communication) at Scale - This is an awesome blog post that goes through the different protocols for Real Time Communications (video calls, audio calls, instant messaging, any form of communication that happens in real time).
The post goes through the components and technologies used for RTC and an overview of the different stacks that are commonly used.
Protocols discussed include WebRTC, Signal Protocol (used by Signal App, WhatsApp, Messenger, Skype, etc.), Real-Time Streaming Protocol (RTSP) and more.
Programming Language Resources - This is a collection of awesome resources for people who want to write programming languages. If you want to build a compiler or a runtime, you should definitely check this out.
A fantastic series of lectures on Distributed Systems by Robert Morris (co-founder of YCombinator).
The lectures cover actual applications, so there are lectures on ZooKeeper, Google Cloud Spanner, Apache Spark and Bitcoin!
Behind the scenes of CPython - A series of blog posts that digs into how CPython (the default and most widely used implementation of Python) works under the hood.
Offline First - Pros and Cons
Over the last decade, we’ve seen a shift from desktop applications to web applications.
Now, users are downloading far fewer applications and are instead using them through the browser.
Offline-First is a paradigm in response to this which states that the software must work as well offline as it does online.
RxDB wrote some awesome opinion articles on the Offline-First paradigm, which you can read here (Offline First explained) and here (Downsides of Offline First).
Here’s a summary of the main concepts discussed in the articles…
The first question is, why even care about offline-first?
Internet connections are getting much more reliable (especially for mobile devices), so it seems like offline-first might be a waste of time.
So, why would you want to rely on browser-side storage?
(By the way, you can read about all the options for browser side storage in a previous email here.)
Some reasons why you should care are
Much better User Experience - In most web apps, many user interactions will require a request to the backend server. This means additional latency and occasional failures.
On the other hand, Offline-First apps direct the majority of operations against local storage which means instant responses.
Better Multi-tab experience - Many websites handle state changes for multi-tab usage poorly. For example, if a user has multiple tabs of a website open and signs in to his account on one tab, the state might not change across all tabs.
On offline first applications, there is one state of the data inside of IndexedDB (or some other client storage API) and all the tabs (of the same origin) share that state.
User-interaction is less of a scaling factor - With traditional web apps, each user interaction can result in multiple requests to the backend server. The more users interact with your app, the more backend resources you have to provision.
On the other hand, Offline-first applications do not scale up with the amount of user actions. Instead, they scale up with the amount of data being sent to the client. Once the data is sent, the user will be sending far fewer requests to the backend servers.
The article discusses a couple more pros that you can read here.
Now, let’s look at the cons of Offline-First apps.
It only works with small datasets - An offline-first app means you must store the full dataset on the first page load. Every ongoing load needs to download new changes to the dataset.
If you want to build an offline-first tool that displays server logs, that won’t work since you can’t send terabytes of log data to the user’s device.
There is a network limit and a limit from the client-side storage APIs.
Browser storage is not really persistent - When you’re storing data in IndexedDB or another storage API, you have a very weak guarantee on durability (you can’t assume the data will stay forever).
You obviously have a much stronger durability guarantee when you’re storing user data on your own databases.
Performance is better than web apps, but not better than native - When you’re creating web based offline-first apps, you cannot store data directly on the user’s filesystem. Instead, there are many layers between your JavaScript code and the filesystem.
However, offline-first apps will generally be fast-enough in most cases. Data will be processed in under 20 milliseconds so you can render the updated UI in the next frame.
You probably won’t have to process a million transactions per second for an offline-first web app since it’s UI based and a user won’t be clicking buttons that fast.
Eventual Consistency - Offline-first apps do not have a single source of truth. There is a source on the backend and one on the user’s browser.
This can be an issue for transactions that are too important to be “eventually consistent”. An example is for a banking application.
A user may transfer money to a friend while his phone is offline. If we wait until the user comes back online (which could be hours) to actually make the transfer, then this could be an issue.
The user thinks he’s already transferred the money but the recipient hasn’t gotten payment.
You can read more cons here.
Interview Question
Given two strings s and t, return the number of distinct subsequences of s which equal t.
A subsequence is a new string formed from the original string by deleting some (or none) of the characters without changing the remaining character’s relative positions.
Example
Input: s = “rabbbit“, t = “rabbit“
Output: 3
Explanation:
There are 3 ways you can generate “rabbit” from “rabbbit”
rabbbit
rabbbit
rabbbit
Here’s the question in LeetCode.
We’ll send the solution in our next email, so make sure you move our emails to primary, so you don’t miss them!
Gmail users—move us to your primary inbox
On your phone? Hit the 3 dots at the top right corner, click "Move to" then "Primary"
On desktop? Back out of this email then drag and drop this email into the "Primary" tab near the top left of your screen
A pop-up will ask you “Do you want to do this for future messages from quastor@substack.com” - please select yes
Apple mail users—tap on our email address at the top of this email (next to "From:" on mobile) and click “Add to VIPs”
Previous Solution
As a reminder, here’s our last question
You’re given an infinite complete binary tree.
Every level of the tree is filled with values from 1 to infinity.
However, the ordering of the nodes has been flipped for even numbered rows, where they go from largest to smallest.
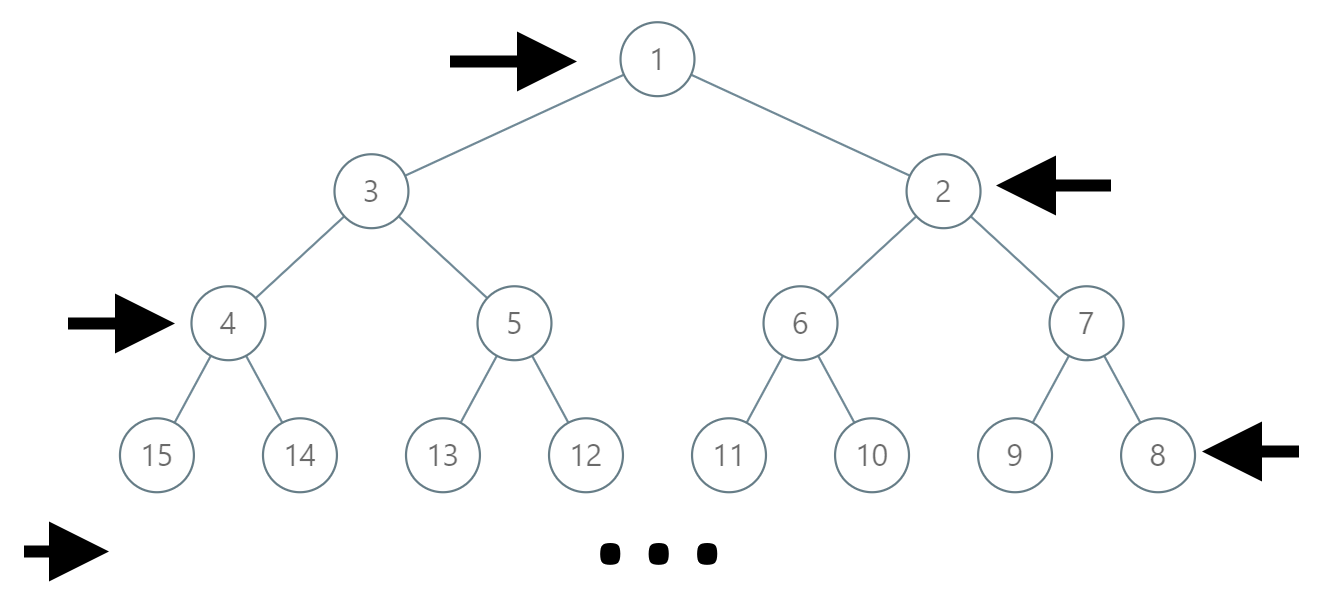
Given the label of a node in this tree, return the labels in the path from the root of the tree to that row.
Example
Input: 14
Output: [1, 3, 4, 14]
Can you solve this in O(log n) time?
Here’s the question in LeetCode
Solution
Your first instinct might be to think of some kind of tree traversal or binary search algorithm.
But, that’s actually wrong.
You don’t need to interact with a binary tree data structure to solve this question!
Instead, try and work backwards.
We’re at the label node, but can we figure out what the parent node is based off the properties of a complete tree?
We can find what level of the tree we’re in by taking int(log(label)) where it’s log base 2. The first level will be level 0.
If our level is even, then the nodes will be ordered from smallest to largest. If our level is odd, then they will be ordered from largest to smallest.
Therefore, we can calculate the label of the first node in our level. If we’re on an even level, then our first node is 2**(level). Otherwise, the first node is 2**(level + 1) - 1.
Now that we have the first node, we can find our current node’s position in the level by subtracting label and first.
Given the current node’s position, our parent node’s position (in its own level) will be the current node’s position divided by 2 (rounded down). That is a property of complete binary trees.
Now, we have to find the first node in our parent node’s level and then we can add our parent node’s position (or subtract, depending on if the parent node’s level is even or odd) to find the parent node’s label.
Now, we repeat the same exact process until we come to our root node, which has the label 1.
While doing the process, we’ll append our labels on to an array that will keep track of the path.