Principles for API Design
Hey Everyone,
Today we’ll be talking about
Slack’s principles for API Design
Good API design can be tricky
It’s important to get right, since making breaking changes to an API will anger your users
Slack has a set of 6 design principles that can help you design better APIs
Why Facebook, WhatsApp and Instagram went down
Facebook had their worst outage since 2008
The issue was related to DNS, specifically BGP routing and BGP announcements
Plus, a couple awesome tech snippets on
Python 3.10
Best practices for Logging
We also have a solution to our last difficult interview question. Plus, a new question from Uber.
Quastor Daily is a free Software Engineering newsletter sends out FAANG Interview questions (with detailed solutions), Technical Deep Dives and summaries of Engineering Blog Posts.
How Slack Designs APIs
It’s extremely important to carefully think about your API design from the beginning.
Designing a bad API means wasting developer time and (for a public API) poor adoption.
It’s also extremely difficult to make breaking changes to an API after shipping so bad API design can be hard to fix.
In order to avoid this at Slack, they’ve published some principles around API design.
Slack’s API Design Principles
Do one thing and do it well - It can be tempting to try and solve too many problems at once. Instead, pick a specific use case and design your API around solving that.
Simple APIs are more easy to understand and easier to scale.
It’s easy to add features to an API, but hard to remove them.
Make it fast and easy to get started - Developers should be able to complete a basic task using your API quickly.
At Slack, they want entry-level developers to be able to learn about the platform, create an app, and send their first API call within 15 minutes.
Strive for intuitive Consistency - Developers should be able to guess parts of your API without reading the documentation.
You can make your API more intuitive with your choices for endpoint names, input parameters and output responses.
Adhere closely with industry standards and also make sure your API is consistent with your product. You should choose field names based on what you call those concepts in your product.
Return meaningful errors - Good error messages are easy to understand, unambiguous and actionable. Implementation details should not leak in your error messages.

Design for scale and performance - While designing an API, you should follow best practices to avoid bad performance. Implement things like
Pagination
Rate Limiting
Avoid breaking changes - A breaking change is any change that can stop an existing client app from functioning as it was before the change.
Avoid these and have an apologetic communication plan if you need to make a breaking change.

Quastor Daily is a free Software Engineering newsletter sends out FAANG Interview questions (with detailed solutions), Technical Deep Dives and summaries of Engineering Blog Posts.
Tech Snippets
The biggest new feature is structural pattern matching.
There are also improvements to the static typing system with union types, type aliases and type guards.
Error messages have gotten a lot better in Python 3.10 with more precise errors for many common issues.
If you’re a backend developer, you probably have some type of a logging system in place. Here are some useful tips to make your logs more meaningful.
Log after, not before - You should be logging things that happened and not things that you’re going to do.

Separate parameters and messages - A typical log message contains two parts: a handwritten message that explains what was going on, and a list of parameters involved. Separate both!

Distinguish between WARNING and ERROR - Log levels exist for a reason, so make sure you use them appropriately.
If you did some operations that worked, but there were some issues then that is a WARNING.
If you did some operation and it didn’t work, then that is an ERROR.
Read the full article for more details (and more best practices)
Quastor Daily is a free Software Engineering newsletter sends out FAANG Interview questions (with detailed solutions), Technical Deep Dives and summaries of Engineering Blog Posts.
Why Facebook, Instagram and WhatsApp went down
Today, services hosted on Facebook infrastructure (Facebook, WhatsApp, Instagram, internal tools at Facebook) were all down for nearly 5 hours.
The issue was with DNS, which is a pretty common point of failure (Microsoft Azure’s outage on April 1rst of this year was also due to DNS).
More specifically, the issue was with Facebook’s Autonomous System and the BGP updates it was broadcasting.
The internet is a network of networks, and Autonomous Systems (AS) are the big networks that make up the internet. Autonomous Systems are made up of many internal networks and the AS tells other ASs that it controls those internal networks by originating “prefixes” (saying they control those IP addresses).
Border Gateway Protocol (BGP) is the network protocol that exchanges routing information between these Autonomous Systems on the internet. Part of BGP’s job is to look at all the available paths that data could travel and picks the best route.
But, in order for BGP to do that, the Autonomous System has to announce it’s prefix routes to the internet using BGP.
So, Facebook’s Autonomous System made BGP announcements withdrawing all the routes to their prefixes at 3:40 PM UTC.
A Reddit user named ramenporn said he worked at Facebook’s Recovery Team and provided an update on what the issue was (he quickly deleted his account after, since Facebook is a publicly traded company and he probably realized he wasn’t authorized to give statements).
As many of you know, DNS for FB services has been affected and this is likely a symptom of the actual issue, and that's that BGP peering with Facebook peering routers has gone down, very likely due to a configuration change that went into effect shortly before the outages happened (started roughly 1540 UTC).
There are people now trying to gain access to the peering routers to implement fixes, but the people with physical access is separate from the people with knowledge of how to actually authenticate to the systems and people who know what to actually do, so there is now a logistical challenge with getting all that knowledge unified.
Part of this is also due to lower staffing in data centers due to pandemic measures.
I believe the original change was 'automatic' (as in configuration done via a web interface). However, now that connection to the outside world is down, remote access to those tools don't exist anymore, so the emergency procedure is to gain physical access to the peering routers and do all the configuration locally.
So, because Facebook’s internal network is entirely self-contained, this meant that Facebook employees couldn’t remotely fix the bad config.
They had to gain physical access to the peering routers.
At 9 PM UTC, there was renewed BGP activity from Facebook’s network which peaked at 9:17 PM UTC.
By 9:20 PM UTC, “www.facebook.com” was resolving to a valid IP address again on Cloudflare.
Interview Question
You are given an integer array called nums. You are also given an integer called target.
Find 3 integers in nums such that the sum is closest to target.
Return the sum of the 3 integers.
Each input will have exactly one solution
Example
Input: nums = [-1, 2, 1, -4], target = 1
Output: 2
The sum that is closest to the target is (-1, 2, 1)
Quastor Daily is a free Software Engineering newsletter sends out FAANG Interview questions (with detailed solutions), Technical Deep Dives and summaries of Engineering Blog Posts.
Previous Solution
As a reminder, here’s our last question
Given two strings s and t, return the number of distinct subsequences of s which equal t.
A subsequence is a new string formed from the original string by deleting some (or none) of the characters without changing the remaining character’s relative positions.
Example
Input: s = “rabbbit“, t = “rabbit“
Output: 3
Explanation:
There are 3 ways you can generate “rabbit” from “rabbbit”
rabbbit
rabbbit
rabbbit
Here’s the question in LeetCode.
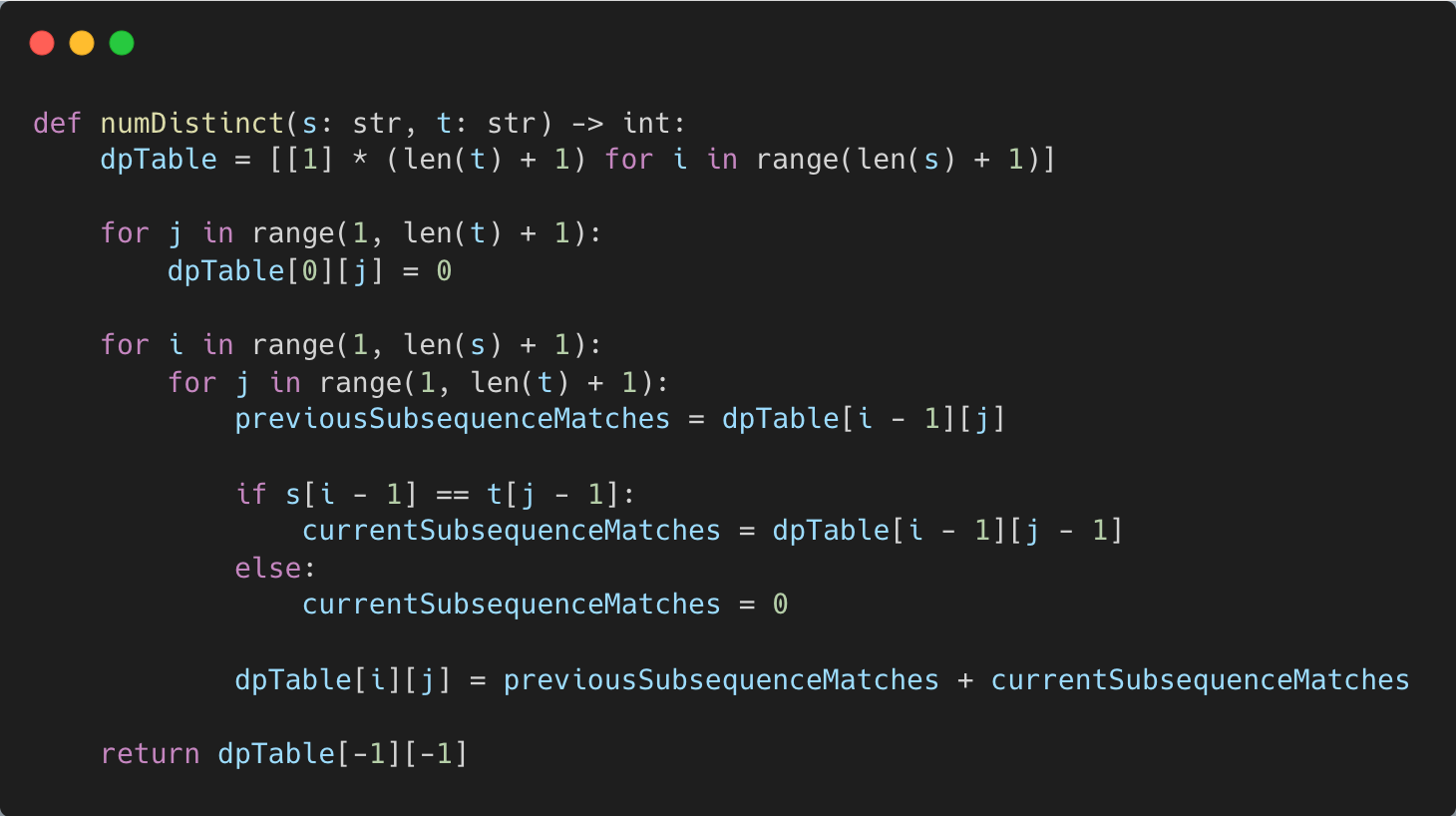
Solution
We can solve this question with Dynamic Programming.
We’ll first start with the top-down solution.
We’ll have a recursive function called _numDistinct.
The function will take two parameters, sCounter and tCounter.
sCounter represents the current index in s and tCounter represents the current index in t.
Now, we’ll iterate through the characters in s from sCounter to the end of s.
For each character, we’ll check if it’s equal to the character at index tCounter in t.
If it is, then we have a possible matching subsequence and we’ll explore this further by recursively calling _numDistinct on the next character in s and t.
Our base case is if tCounter == len(t). That means we’ve reached the end of t and found a valid subsequence.
If tCounter != len(t) but sCounter == len(s), then that’s our second base case. That means we’ve reached the end of s but we haven’t found a valid subsequence.
In order to avoid repeat computations, we’ll add a memo table as a cache.
Here’s the Python 3 code for the top down solution.
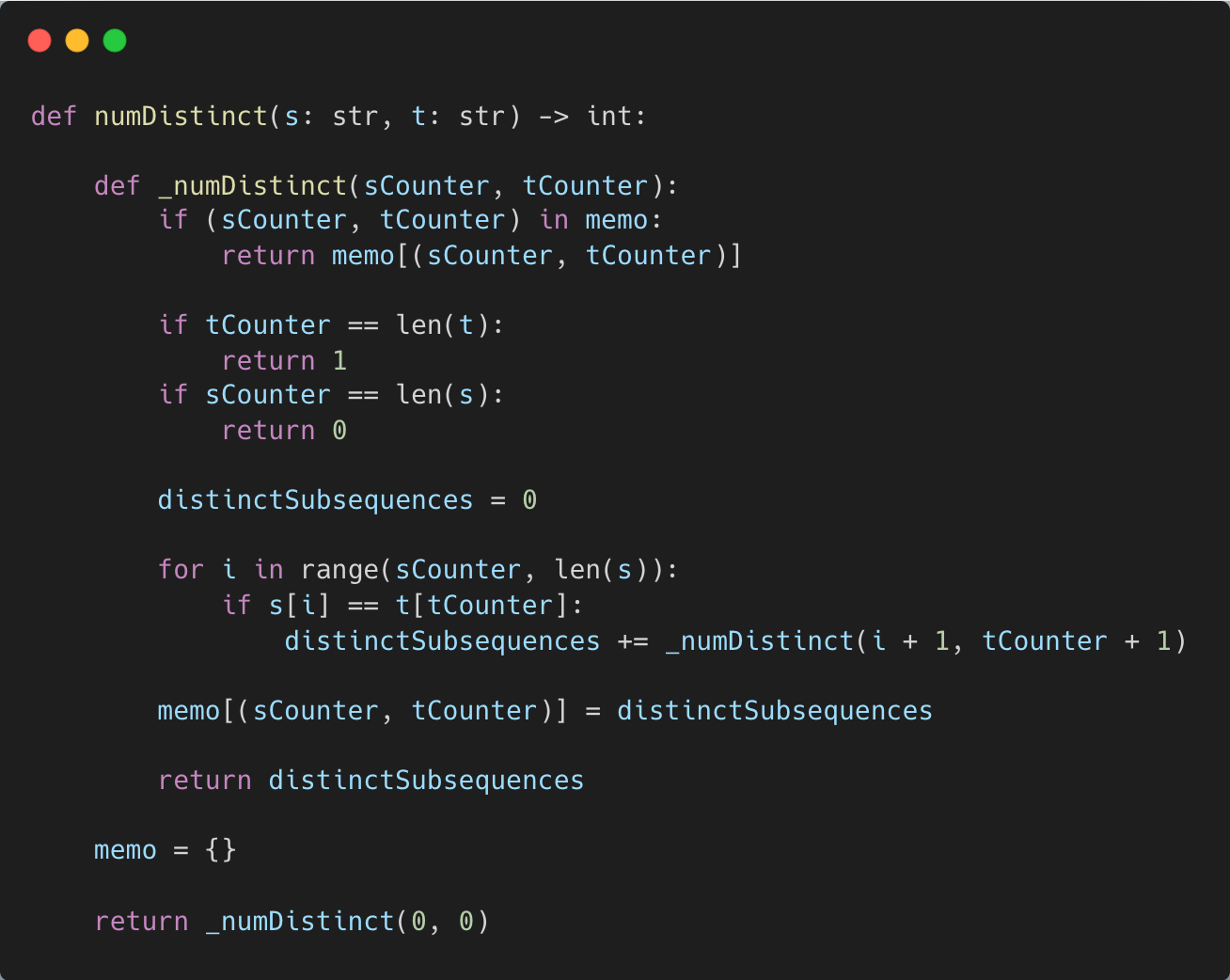
However, this code will still give you a “time limit exceeded” error on LeetCode.
In order to pass all test conditions, you’ll have to flip the code around to come up with the bottom-up DP solution.
You can do that with a DP table.
Here’s the Python 3 code for the bottom up solution.