


Rate Limiting at Stripe
Hey Everyone,
Today we’ll be talking about
Using Rate Limiters and Load Shedding
What’s Rate Limiting and what’s Load Shedding
The different types of limiters Stripe uses in production
Different algorithms for building a rate limiter
How computers in a distributed system synchronize their clocks
The clock synchronization problem
How computers do this using NTP (Network Time Protocol)
Brief overview of how NTP works
Plus, a couple awesome tech snippets on
Concurrency in Java vs. Go
Text extraction in PDF files
We have a solution to our last coding interview question on checking a Sudoku board, plus a new question from Amazon.
If you find Quastor useful, be sure to sign up!
Scaling an API with Rate Limiters
Stripe Engineering wrote a fantastic blog post on how they think about rate limiters.
Here’s a summary.
Rate Limiting is a technique used to limit the amount of requests a client can send to your server.
It’s incredibly important to prevent DoS attacks from clients that are (accidentally or maliciously) flooding your server with requests.
A rule of thumb for when you should use a rate limiter is if your users can reduce the frequency of their API requests without affecting the outcome of their requests, then a rate limiter is appropriate.
For example, if you’re running Facebook’s API and you have a user sending 60 requests a minute to query for their list of Facebook friends, you can rate limit them without affecting their outcome. It’s unlikely that they’re adding new Facebook friends every single second.
Rate Limiting is great for day-to-day operations, but you’ll occasionally have incidents where some component of your system is down and you can’t process requests at your normal level.
In these scenarios, Load Shedding is a technique where you drop low-priority requests to make sure that critical requests get through.
Stripe is a payment processing company (you can use their API to collect payments from your users) so a critical request for them is a request to create a charge.
An example of a non-critical method would be a request to read charge data from the past.
Stripe uses 4 different types of limiters in production (2 rate limiters and 2 load shedders).
Request Rate Limiter
Restricts each user to n requests per second. However, they also built in the ability for a user to briefly burst above the cap to handle legitimate spikes in usage.
Concurrent Requests Limiter
Restricts each user to n API requests in progress at the same time.
This helps stripe manage the load of their CPU-intensive API endpoints.
Fleet Usage Load Shedder
Stripe divides their traffic into two types: critical API methods and non-critical methods.
An example of a critical method would be creating a charge (charging a customer for something), while a non-critical method is listing a charge (looking at past charges).
Stripe always reserves a fraction of their infrastructure for critical requests. If the reservation number is 10%, then any non-critical request over the 90% allocation would be rejected with a 503 status code.
Worker Utilization Load Shedder
Stripe uses a set of workers to independently respond to incoming requests in parallel. If workers start getting backed up with requests, then this load shedder will shed lower priority traffic.
Stripe divides their traffic into 4 categories
Critical Methods
POSTs
GETs
Test mode traffic (traffic from developers testing the API and making sure payments are properly processed)
If worker capacity goes below a certain threshold, Stripe will begin shedding less-critical requests, starting from test mode traffic.
Building a rate limiter in practice
There are quite a few algorithms you can use to build a rate limiter. Algorithms include
Token Bucket - Every user gets a bucket with a certain amount of “tokens”. On each request, tokens are removed from the bucket. If the bucket is empty, then the request is rejected.
New tokens are added to the bucket at a certain threshold (every n seconds). The bucket can hold a certain number of tokens, so if the bucket is full of tokens then no new tokens will be added.
Fixed Window - The rate limiter uses a window size of n seconds for a user. Each incoming request from the user will increment the counter for the window. If the counter exceeds a certain threshold, then requests will be discarded.
After the n second window passes, a new window is created.
Sliding Log - The rate limiter track’s every user’s request in a time-stamped log. When a new request comes in, the system calculates the sum of logs to determine the request rate. If the request rate exceeds a certain threshold, then it is denied.
After a certain period of time, previous requests are discarded from the log.
Stripe uses the token bucket algorithm to do their rate limiting.
Tech Snippets
Why you can have millions of Goroutines but only thousands of Java Threads
If you’ve been working with JVM based languages for a while, you’ve probably come across a situation where you’ve reached the limit of the number of concurrent threads you can have.
On your personal computer, this limit is usually around ~10,000 threads.
On the other hand, you can have more than a hundred million goroutines on a laptop with Go.
This article explores why you can have so many more Goroutines than threads.
There’s two main reasons why
The JVM delegates threading to operating system threads. Go implements its own scheduler that allows many Goroutines to run on the same OS thread.
The JVM defaults to a 1 MB stack per thread. Go’s stacks are dynamically sized and a new goroutine will have a stack of about 4 KB.
What’s so hard about PDF text extraction?
Extracting text data from PDF documents is actually a harder problem than you might imagine. This article goes into some of the issues that come up.
You might be wondering why not use an OCR algorithm? Well, using OCR is far more compute-intensive than just extracting the text directly from the PDF.

Clock Synchronization and NTP
When you’re talking about measuring time, the gold standard is an atomic clock. Atomic clocks have an error of ~1 second in a span of 100 million years.
However, Atomic clocks are way too expensive and bulky to put in every computer. Instead, individual computers contain quartz clocks which are far less accurate.
The clock drift differs on the hardware, but it’s an error of ~10 seconds per month.
When you’re dealing with a distributed system with multiple machines, it’s very important that you have some degree of clock synchronization.
Clock skew is a measure that tells you the difference between two clocks on different machines at a certain point of time.
You can never reduce clock skew to 0, but you want to reduce clock skew as much as possible through the synchronization process.
The way clock synchronization is done is with a protocol called NTP, Network Time Protocol.
NTP works by having servers that maintain accurate measures of the time. Clients can query those servers and ask for the current time.
The client will then adjust its own time based on the time that it got from the server.
Here’s a list of NTP servers that you can query for the current time. It’s likely that your personal computer uses NTP to contact a time server and adjust its own personal clock.
My personal computer uses time.apple.com as its NTP time server.
It’s not possible for every computer in the world to directly query an atomic clock since there aren’t enough atomic clocks in the world to satisfy that demand.
Therefore, there are some NTP servers in between your computer and the reference clock.
NTP arranges these servers into strata
Stratum 0 - atomic clock or GPS receiver
Stratum 1 - synced directly with a stratum 0 device
Stratum 2 - servers that sync with stratum 1 devices
Stratum 3 - servers that sync with stratum 2 devices
And so on until stratum 15. Stratum 16 is used to indicate that a device is unsynchronized.
A computer may query multiple NTP servers, discard any outliers (in case of faults with the servers) and then average the rest.
Computers may also query the same NTP server multiple times over the course of a few minutes and then use statistics to reduce random error due to variations in network latency.
For connections through the public internet, NTP can usually maintain time to within tens of milliseconds (a millisecond is one thousandth of a second).
To learn more about NTP, watch the full lecture by Martin Kleppmann.
Interview Question
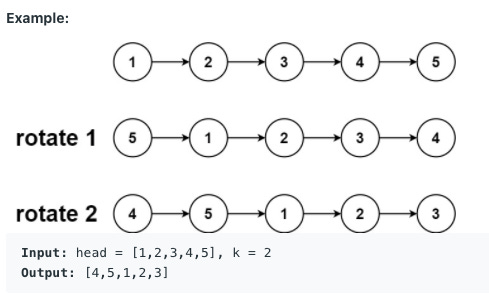
You are given the head of a linked list and an integer k.
Rotate the linked list to the right by k places.
We’ll send the solution in our next email, so make sure you move our emails to primary, so you don’t miss them!
Gmail users—move us to your primary inbox
On your phone? Hit the 3 dots at the top right corner, click "Move to" then "Primary"
On desktop? Back out of this email then drag and drop this email into the "Primary" tab near the top left of your screen
A pop-up will ask you “Do you want to do this for future messages from quastor@substack.com” - please select yes
Apple mail users—tap on our email address at the top of this email (next to "From:" on mobile) and click “Add to VIPs”
Previous Solution
As a reminder, here’s our last question
You are given a 2-D array that represents a 9x9 Sudoku board. Some of the cells in board will be filled, while others are empty.
Return true if the board is valid.
In order to be valid, it must satisfy the following rules…
Each row cannot repeat any of the digits from 1 to 9.
Each column cannot repeat any of the digits from 1 to 9.
Each 3x3 sub-box of the grid cannot repeat any of the digits from 1 to 9.
A partially filled Sudoku board can be valid as long as it doesn’t violate any of those 3 rules.

Here’s the question in LeetCode
Solution
We can solve this question by just checking all the rows, columns and squares and making sure that none of the numbers repeat.
We’ll create 3 arrays.
One array will keep track of the rows. It will have 9 elements and each element will be a set that keeps track of the elements in that row.
One array will keep track of the columns. It will have 9 elements and each element will be a set that keeps track of the elements in that column.
One array will keep track of the 3x3 squares. It will have 3 elements and each element will be another array. Inside each inner-array will be 3 elements and each of those elements will be a set. Each set keeps track of a 3x3 square.
We’re using sets because checking if an integer is in a set can be done in constant time.
Now, we just iterate through every element in our sudoku board and check our different arrays to see if the element already exists in its row, column or square.
If yes, then we can immediately return False.
Otherwise, we’ll add the element to its respective row, column and square.
When we’ve finished iterating through the entire sudoku board, we can return True.
Here’s the Python 3 code. What’s the time and space complexity of our solution? Reply back with your answer and we’ll tell you if you’re right/wrong.
