


Reliability Engineering at BlackRock
Hey Everyone!
Today we’ll be talking about
How BlackRock ensures high availability
Aladdin is a technology platform that BlackRock develops to help asset managers track their portfolios and manage risk. Trillions of dollars are tracked with Aladdin
Fulfilling Aladdin’s SLOs are extremely important so engineers at BlackRock have developed a robust Telemetry & Alert platform
We discuss the platform’s architecture and talk about design choices that were made.
DoorDash’s migration to Next.js and Server-Side Rendering
Client Side Rendering vs. Server Side Rendering
How DoorDash monitored performance of the website
Migrating to Next.js without hurting productivity for other teams at the company
Plus, some tech snippets on
How APIs are designed at Slack
A free textbook for Coding Interviews
How an engineering manager at Reddit interviews candidates
We also have a solution to our last interview question and a new question from Google.
Quastor is a free Software Engineering newsletter that sends out summaries of technical blog posts, deep dives on interesting tech and FAANG interview questions and solutions.
Site Reliability Engineering at BlackRock
BlackRock is the world's biggest Asset Manager with more than $10 trillion in assets under management.
In addition to being an asset manager, BlackRock is also a technology company. They sell a variety of software to other asset managers, banks, insurance companies, etc.
Their biggest product is Aladdin, the financial industry's most popular software platform for investment management. Asset managers (banks, pension funds, hedge funds, etc.) use Aladdin to track profit/loss, manage portfolio risk, make trades, analyze historical data, etc.
In 2013, the Aladdin platform was used to manage more than 7% of the world's 225 trillion dollars of financial assets (and it's grown since then), so any issues with the platform can have major consequences on the global financial system.
BlackRock's Site Reliability Engineering team has built a robust telemetry platform to oversee the health, performance and reliability of Aladdin.
Sudipan Mishra is an engineer on BlackRock's SRE team and he wrote a great blog post on the architecture of their Telemetry platform.
Here's a summary
Architecture of the Telemetry Platform
All the various components of Aladdin generate large amounts of logs, data, etc.
The Telemetry platform is responsible for aggregating all these reports, displaying them, and sending alerts to the various Aladdin developers at BlackRock if one of their services is not performant.
Here's the architecture.

At the top you have all the various apps, databases, infrastructure and pipelines involved in the Aladdin platform. All of these report metrics which are then read by the Telemetry platform's collectors.
From the collector, these metrics go to a Catalog server, an internally developed service that manages which metrics should be cataloged.
Some metrics might be too noisy/unnecessary so engineers can remove them from the Telemetry Catalog UI.
The metrics that get passed on are then sent from the Collector to Kafka and eventually to Prometheus. Prometheus is an open source systems monitoring and alerting toolkit that was originally developed at SoundCloud.
From Prometheus, the metrics go to InfluxDB, AlertManager and Grafana.
InfluxDB is an open source time series database that BlackRock uses for long-term storage of all the telemetry metrics.
AlertManager is a tool in the Prometheus toolkit that triggers alerts to BlackRock engineers based on the metrics.
Grafana is another Prometheus tool that lets engineers produce dashboards and charts to visualize the telemetry metrics.
Alerting Strategy
Prometheus' AlertManager will send alerts to the various developers working on Aladdin based on the telemetry. A team should be alerted as quickly as possible if any incidents have an impact on their service.
However, if the SRE team isn't careful about how they implement alerts then they can cause things like alarm fatigue.
The SRE team has 4 core principles for their alerts
1. Actionable - Every alert should clearly define what is broken or about to break. Alerts should also propose the corrective actions to take.
2. Effective - False positives (issuing an alert when there is no incident) and False negatives (not triggering an alert despite there being an issue) must both be minimized/eliminated. Otherwise, they can cause mistrust in the alerting system.
3. Impactful - Developers should not be getting alerts for trivial/unimportant things. Otherwise, developers can get alarm fatigue and accidentally ignore important alerts.
4. Transparent - As developers onboard new applications, they should know what alerts they're going to be getting. They should also have an idea of how many alerts they'll typically see for that app.
BlackRock evaluated different types of alert systems to meet all of these principles.
You can read about some of the options in Google's SRE book. The book is free and definitely a must-read if you're interested in SRE.
BlackRock's SRE team decided to go with a Multiwindow, Multi-Burn-Rate Alerting Strategy. This is #6 on Google's list of alert types in the Google SRE Workbook.
You see how much error is allowable and set various limits around that. As you notice errors in the telemetry, you "burn" against the allowable error limit. Once you surpass that allowable limit (and if there are still errors coming) then you send an alert.
BlackRock found this strategy to have a low false-positive rate, a low false-negative rate, a fast detection time and a very low reset time.
In order to test their alerting strategy, they wrote a script that would let developers extract metrics from their Prometheus instance for a given time and date range. They can take those metrics and then backtest their alert strategy to see how many alerts they would've gotten and whether there would've been any false negatives or false positives.
For more details, you can read the full article here.
Quastor is a free Software Engineering newsletter that sends out summaries of technical blog posts, deep dives on interesting tech and FAANG interview questions and solutions.
Tech Snippets
How APIs are Designed at Slack - A great blog post by Slack Engineering going through their design philosophy and process for APIs.
Competitive Programmer's Handbook - This is an awesome free textbook that goes through all the major concepts and patterns you need to know for competitive programming. It’s also extremely helpful for coding interviews!
Reddit Interview Problems: The Game of Life - Alex Golec, an engineering manager at Reddit, goes through an interview problem he used to use to screen candidates. He talks about how he evaluated candidate responses to the question and why he thinks it’s a good question.
Funny enough, the question Alex goes through in this blog post is already published on LeetCode. You can view it here.
It might be interesting to try and solve the question yourself and see how far you can get before reading Alex’s solution (and evaluation criteria).
DoorDash’s Migration to Next.js
DoorDash is the largest food delivery app in the United States with more than 20 million customers and 450,000 restaurants. The company maintains a mobile app but also allows users to order food using the DoorDash website.
DoorDash’s website was built with ReactJS and made heavy use of Client-Side Routing. On the first visit, the site would send the user a large bundle of HTML/CSS/JavaScript and the user could browse the site as a single page application (SPA). The web browser renders the page.
This means a native-app like experience after the bundle is loaded, but it also means a poor experience while the user is waiting for the bundle. Using client-side routing was resulting in loading issues, poor SEO, and other problems.
To fix this, DoorDash engineers pivoted to using a React framework called Next.js, to implement Server Side Rendering (SSR) for their high traffic pages. SSR is a trend back from Single-Page-Applications to the “old” way of generating the HTML pages on the backend.
You can implement SSR with React, but Next.js is a framework that makes it much easier to do. The Next.js framework has seen huge growth over the last few years.
Patrick El-Hage and Duncan Meech are two software engineers on the client platform team at DoorDash and they wrote a great blog post about switching over to Next.js for the DoorDash website.
Here’s a summary
DoorDash was interested in moving the site from client-side rendering to server-side rendering.
By doing so, engineers hoped to make the user experience better by reducing the initial page load time. With SSR, DoorDash could reduce the bundle size on the initial load significantly.
This would result in SEO improvements since Google favors websites that score higher on their web metrics and because Google still has trouble crawling single page applications.
DoorDash engineers used webpagetest.org to measure the performance of the pre-SSR pages and to confirm the performance gains on the new SSR pages. The site lets you measure performance across a variety of devices and network conditions.
The engineers also look at Google web vitals like
Largest Contentful Paint - Measures loading performance. How long does it take to render the largest image or text block visible on the page?
First Input Delay - Measures interactivity. It is the time from when a user first interacts with a page (click a link, button, etc.) to the time when the browser is able to begin processing event handlers in response to that interaction.
Cumulative Layout Shift - Measures visual stability. It measures any unexpected layout shifts that occur during the lifespan of the web page. Having an ad pop up and block content 3 seconds after the page loads will hurt your CLS score.
Implementing SSR without Downtime
DoorDash wanted to deploy SSR incrementally to avoid any negative experiences for customers.
Therefore, they configured a reverse proxy that would direct a certain amount of traffic to the new Next.js app and the rest of the traffic to the old client-side rendered app. This proxy would also handle scaling concerns like logging, circuit breaking, timeouts, etc.
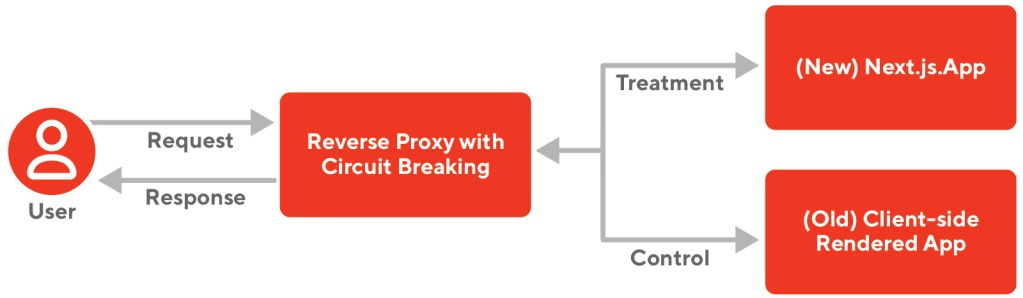
The new Next.js app was hosted on Express.js using Next’s Custom Server feature.
In addition to avoiding downtime for customers, DoorDash engineers also had to make sure that the Next.js adoption didn’t impact other developers at the company. The migration could not block rollouts and product launches from other teams.
Therefore, the client platform team had both the Next.js app and the legacy client-side-rendered app in the same codebase and they maximized code reuse.
Other teams could build out their features without concern for how those features would eventually integrate with Next.js and SSR paradigms.
During code review, the client platform team would ensure that the new features were SSR compatible.
The migration to Next.js was done incrementally where the team migrated page by page. This way, they could learn quickly and immediately see performance wins for customers without going through a large rewrite that could take months.
They used a “trunk-branch-leaf” strategy for the migration where they focused their efforts on components close to the top of the hierarchy of components on the page. Components lower in the hierarchy were left untouched.
As they shift to Next.js, DoorDash engineers are employing several strategies to make sure the new system scales.
Server side rendering means more compute on your servers compared to client side rendering, so DoorDash did load testing using tools like Vegeta.
They also implemented load shedding and circuit breaking into their reverse proxy server so it would detect if the new service was failing requests or timing out and direct requests back to the old experience.
They used Opossum, a node.js circuit breaker, to handle sending requests back to the legacy system if the Next.js system wasn’t able to handle them.
Despite the concerns, DoorDash saw great results with the migration. Next.js pages achieved 12%+ faster page load times and LCP (one of Google’s core speed metrics) has improved 65%+.
Read the full article for more details
Interview Question
Design an algorithm to encode a list of strings to a single string.
This encoded string will be sent over a network to another computer, where it will be decoded back to the original list of strings.
Implement the encode and decode functions.
Here’s the question in LintCode
(it’s also available on leetcode but only to leetcode premium members).
Previous Question
As a refresher, here’s the previous question
How would you build a spelling correction system?
Possible Follow On Questions
How would you check if a word is misspelled?
How would you find possible suggestions?
How would you rank the suggestions for the user?
Solution
The core idea for most spell-check systems is based on the Levenshtein distance.
You can think of Levenshtein distance as the minimum number of single-character edits (insertion, deletions or substitutions) required to change one word into the other word.
The Levenshtein distance from the intended word should be one or two edits. Therefore, if we can keep a hash table for all the words in our dictionary and then look for words that have a Levenshtein distance of 2 or less from the text, we can find the intended word. If the text is already in our dictionary, then it’s not misspelled.
The words in our dictionary that have a Levenshtein distance of 2 or less from our text may be too many to list out for the user. Therefore, it’s important that we rank our suggestions and implement a cut-off for the number of suggestions that we list. There are several ways of ranking our suggestions
History of refinements - users often provide a great amount of data about the most likely misspellings by first entering a misspelled word and then correcting it. This data can be collected and then used to implement rankings.
Typing errors model - spelling mistakes are usually a result of typing errors (typos). Therefore, these errors can be modeled based on the layout of a keyboard (mran -> mean)
Phonetic modeling - spelling errors also happen when the user knows how the word sounds but doesn’t know the exact spelling. Therefore, we can map the text to phonemes and then find all the words that map to the same phonetic sequence.
Quastor is a free Software Engineering newsletter that sends out summaries of technical blog posts, deep dives on interesting tech and FAANG interview questions and solutions.