
The Architecture of Apache Spark
Hey Everyone,
Today we’ll be talking about
The Architecture of Apache Spark
A brief intro to MapReduce and issues with Hadoop MapReduce
How Apache Spark fixes MapReduce’s pain points and features that Spark provides
Spark’s leader-worker architecture with drivers and executors
Resilient Distributed Datasets and their properties
Directed Acyclic Graphs and the Spark DAG Scheduler
Plus some tech snippets on
How to do a Migration by Gergely Orosz
How OpenGL works
New WebKit Features in Safari 15.4
A great GitHub repo with resources for CTOs (or aspiring CTOs)
Questions? Please contact me at arpan@quastor.org.
Quastor is a free Software Engineering newsletter that sends out deep dives on interesting tech, summaries of technical blog posts, and FAANG interview questions and solutions.
The Architecture of Apache Spark
Spark is an open source project that makes it much easier to run computations on large, distributed data. It’s widely used to run datacenter computations and its popularity has been exploding since 2012.
It’s now become one of the most popular open source projects in the big data space and is used by companies like Amazon, Tencent, Shopify, eBay and more.
Before Spark, engineers relied on Hadoop MapReduce to run computations on their data, but there were quite a few issues with that approach.
Spark was introduced as a way to solve those pain points, and it’s quickly evolved into much more.
We’ll talk about why Spark was created, what makes Spark so fast and how it works under the hood.
We’ll start with a brief overview of MapReduce.
History of MapReduce
In a previous tech dive, we talked about Google MapReduce and how Google was using it to run massive computations to help power Google Search.
MapReduce introduced a new parallel programming paradigm that made it much easier to run computations on massive amounts of distributed data.
Although Google’s implementation of MapReduce was proprietary, it was re-implemented as part of Apache Hadoop.
Hadoop gained widespread popularity as a set of open source tools for companies dealing with massive amounts of data.
How MapReduce Works
Let’s say you have 100 terabytes of data split across 100 different machines. You want to run some computations on this data.
With MapReduce, you take your computation and split it into a Map function and a Reduce function.
You take the code from your map function and run it on each of the 100 machines in a parallel manner.
On each machine, the map function will take in that machine’s chunk of the data and output the results of the map function.
The output will get written to local disk on that machine (or a nearby machine if there isn’t enough space on local).
Then, the reduce function will take in the output of all the map functions and combine that to give the answer to your computation.
Issues with MapReduce
The MapReduce framework on Hadoop had some shortcomings that were becoming big issues for engineers.
Iterative Jobs - A common use case for MapReduce is to stack multiple MapReduce jobs sequentially, and run them one after the other.
MapReduce will write to disk after both the Map and Reduce steps, so this leads to a huge amount of disk I/O.
Disk I/O can obviously be very slow, so this caused large MapReduce jobs (involving multiple MapReduce steps one after another) to be very slow and take hours/days.
Interactive Analysis - When you store data on Hadoop (using HDFS), you’ll want to run ad-hoc exploratory queries to better understand your data. Doing this with MapReduce can be a pain because of how unintuitive it can be to create Map and Reduce functions to do your data exploration.
Instead, you’ll use something like Hive (an SQL query engine for Hadoop) so you can just write SQL queries to view your data. However, with Hadoop, Hive will be executing those SQL queries using MapReduce, which means significant latency for the reasons described above (lots of disk I/O).
Lack of Flexibility - Hadoop MapReduce works for general batch processing tasks, but it becomes very unwieldy for handling other workloads like machine learning, streaming, or interactive SQL queries (described above). Turning complex jobs into Map and Reduce functions can be difficult.
This meant that other tools had to be developed to handle those workloads like Hive, Storm, Mahout, etc.
Creation of Apache Spark
Apache Spark was created as a successor to MapReduce to ease these problems.
The main goal was to create a fast and versatile tool to handle distributed processing of large amounts of data. The tool should be able to handle a variety of different workloads, with a specific emphasis on workloads that reuse a working set of data across multiple operations.
Many common machine learning algorithms will repeatedly apply a function to the same dataset to optimize a parameter (ex. Gradient descent).
Running a bunch of random SQL queries on a dataset to get a feel for it is another example of reusing a working set of data across multiple operations (SQL queries in this scenario).
Spark is designed to handle these operations with ease.
Overview of Spark
Spark is a program for distributed data processing, so it runs on top of your data storage layer. You can use Spark on top of Hadoop Distributed File System, MongoDB, HBase, Cassandra, Amazon S3, RDBMSs and a bunch of other storage layers.
In a Spark program, you can transform your data in different ways (filter, map, intersection, union, etc.) and Spark can distribute these operations across multiple computers for parallel processing.
Spark offers nearly 100 high-level, commonly needed data processing operators and you can use Spark with Scala, Java, Python and R.
Spark also offers libraries on top to handle a diverse range of workloads.
Spark SQL will let you use SQL queries to do data processing.
Spark MLlib has common machine learning algorithms like logistic regression.
Spark Structured Streaming lets you process real-time streaming data from something like Kafka or Kinesis.
GraphX will let you manipulate graphs and offers algorithms for traversal, connections, etc. You can use algorithms like pagerank, triangle counting and connected components.
Why is Spark Fast?
Spark’s speed comes from two main architectural choices
Lazy Evaluation - When you’re manipulating your data, Spark will not execute your manipulations (called transformations in Spark lingo) immediately.
Instead, Spark will take your transformations (like sort, join, map, filter, etc.) and keep track of them in a Directed Acyclic Graph (DAG). A DAG is just a graph (a set of nodes and edges) where the nodes have directed edges (the first transformation will point to the second transformation and so on) and the graph has no cycles.
Then, when you want to get your results, you can trigger an Action in Spark. Actions trigger the evaluation of all the recorded transformations in the DAG.
Because Spark knows what all your chained transformations are, Spark can then use its optimizer to construct the most efficient way to execute all the transformations in a parallel way. This helps make Spark much faster.
In Memory - We’ve said several times above that one of the issues with MapReduce is all the disk I/O. Spark solves this by retaining all the intermediate results in memory.
After you trigger an Action, Spark will be calculating all the transformations in RAM using the memory from all the machines in your Spark cluster and then run the computations.
If you don’t have enough RAM, then Spark can also use disk and swap data between the two.
Architecture of Spark
As we said before, Spark is a distributed data processing engine that can process huge volumes of data distributed across thousands of machines.
The collection of machines is called a Spark cluster and the largest Spark cluster is around 8000 machines. (Note. You can also run Spark on a single machine. If you want, you can download it from the Apache website )
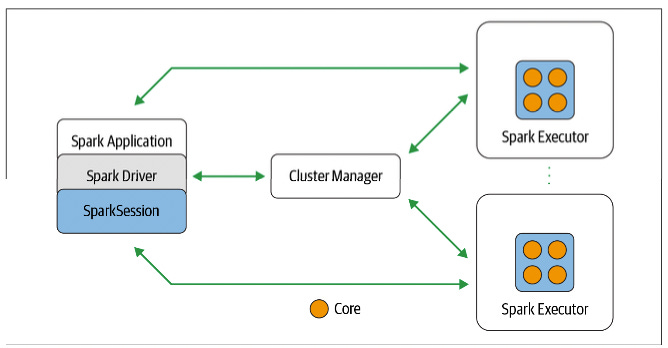
Leader-Worker Architecture
Spark is based on a leader-worker architecture. In Spark lingo, the leader is called the Spark driver while the worker is called the Spark executor.
A Spark application has a single driver, where the driver functions as the central coordinator. You’ll be interacting with the driver with your Scala/Python/R/Java code and you can run the driver on your own machine or on one of the machines in the Spark cluster.
The executors are the worker processes that execute the instructions given to them by the driver. Each Spark executor is a JVM process that is run on each of the nodes in the Spark cluster (you’ll mostly have one executor per node).
The Spark executor will get assigned tasks that require working on a partition of the data that is closest to them in the cluster. This helps reduce network congestion.
When you’re working with a distributed system, you’ll typically use a cluster manager (like Apache Mesos, Kubernetes, Docker Swarm, etc.) to help manage all the nodes in your cluster.
Spark is no different. The Spark driver will work with a cluster manager to orchestrate the Spark Executors. You can configure Spark to use Apache Mesos, Kubernetes, Hadoop YARN or Spark’s built-in cluster manager.
Resilient Distributed Dataset
When Spark runs your computations on the given datasets, it uses a data structure called a Resilient Distributed Dataset (RDD).
RDDs are the fundamental abstraction for representing data in Spark and they were first introduced in the original Spark paper.
Spark will look at your dataset across all the partitions and create an RDD that represents it. This RDD will then be stored in memory where it will be manipulated through transformations and actions.
The key features of RDDs are
Resilience - RDDs are fault-tolerant and able to survive failures of the nodes in the Spark cluster. As you call transformation operations on your RDD, Spark will be building up a DAG of all the transformations. This DAG can be used to track the data lineage of all the RDDs so you can reconstruct any of the past RDDs if one of the machines fails.
Just note, this is fault tolerance for the RDD, not for the underlying data. Spark is assuming that the storage layer (HDFS, S3, Cassandra, whatever) is handling redundancy for the underlying data.
Distributed - Spark assumes your data is split across multiple machines so RDDs are also split across a cluster of machines. Spark will place executors close to the underlying data to reduce network congestion.
Immutability - RDDs are immutable. When you apply transformations to an RDD, you don’t change that RDD but instead create a new RDD. Immutability means every RDD is a deterministic function of the input. This makes caching, sharing and replication of RDDs much easier.
Directed Acyclic Graph
As you’re running your transformations, Spark will not be executing any computations.
Instead, the Spark driver will be adding these transformations to a Directed Acyclic Graph. You can think of this as just a flowchart of all the transformations you’re applying on the data.
Once you call an action, then the Spark driver will start computing all the transformations. Within the driver are the DAG Scheduler and the Task Scheduler. These two will manage executing the DAG.
When you call an action, the DAG will go to the DAG scheduler.
The DAG scheduler will divide the DAG into different stages where each stage contains various tasks related to your transformations.
The DAG scheduler will run various optimizations to make sure that the stages are being done in the most optimal way to eliminate any redundant computations. Then, it will create a set of stages and then pass this to the Task Scheduler.
The Task Scheduler will then coordinate with the Cluster Manager (Apache Mesos, Kubernetes, Hadoop YARN, etc.) to execute all the stages using the machines in your Spark cluster and get the results from the computations.
Quastor is a free Software Engineering newsletter that sends out deep dives on interesting tech, summaries of technical blog posts, and FAANG interview questions and solutions.
Tech Snippets
Migrations Done Well - Gergely Orosz was previously an Engineering Manager at Uber, where he worked on the Payments Experience Platform. He’s currently writing an amazing series of blog posts on how do execute a migration.
How OpenGL works - This is an awesome series of lessons on building a software rasterizer in 500 lines of code (without third party libraries doing the work).
This is part of a series that Dmitry Sokolov has written where he also builds a raytracer, raycaster and more. You can view all his projects here.
New WebKit Features in Safari 15.4 - WebKit is the browser engine that Safari uses. With the launch of Safari 15.4, WebKit has a ton of new features around rendering HTML, CSS Typography and more.
This blog post goes through all the new features added.
An awesome Github Repo on resources for CTOs (or aspiring CTOs).
The repo contains resources on
Software Development Processes (Scrum/Agile, CI/CD, etc.)
Software Architecture
Product Management
Hiring for technical roles
Interview Question
Write a function that checks whether an integer is a palindrome.
For example, 191 is a palindrome, as well as 111. 123 is not a palindrome.
Do not convert the integer into a string.
Quastor is a free Software Engineering newsletter that sends out deep dives on interesting tech, summaries of technical blog posts, and FAANG interview questions and solutions.