
The Architecture of Databases
Hey,
Today we’ll be talking about
The Architecture of Databases - This is a brief snippet from the amazing book Database Internals by Alex Petrov
The various components: Transport System, Query Processor, Execution Engine, and the Storage Engine
How these components interact with each other
Plus some tech snippets on
An amazing GitHub repo on Security Engineering
Extreme HTTP Performance Tuning
How to build a second brain as a software engineer
A 4-part blog series on how Google Chrome works
Questions? Please contact me at arpan@quastor.org.
Quastor is a free Software Engineering newsletter that sends out summaries of technical blog posts, deep dives on interesting tech and FAANG interview questions and solutions.
The Architecture of Databases
Alex Petrov is a software engineer at Apple. He wrote an amazing book on Database Internals, where he does a deep dive on how distributed data systems work. I’d highly recommend you pick up a copy if you want to learn more on the topic.
We’ll be summarizing a small snippet from his book on the architecture behind Database Management Systems (DBMSs).
Summary
You’ve probably used a DBMS like Postgres, MySQL, etc.
They provide an extremely useful abstraction that you can use in your applications for storing and (later) retrieving data.
All DBMSs provide an API that you can use through some type of Query Language to store and retrieve data.
They also provide a set of guarantees around how this data is stored/retrieved. A couple examples of such guarantees are
Durability - guarantees that you won’t lose any data if the DBMS crashes
Consistency - After you write data, will all subsequent reads always give the most recent value of the data? (this is important for distributed databases)
Read/Write Speeds - IOPS is the standard measure of input and output operations per second on storage devices.
The architecture of the various Database Management Systems vary widely based on their guarantees and design goals. A database designed for OLTP use will be designed differently than a database meant for OLAP.
An in-memory DBMS (designed to store data primarily in memory and use disk for recovery and logging) will also be designed differently than a disk-based DBMS (designed to primarily store data on disk and use memory for caching).
However, databases have some common themes in their various architectures and knowing these themes can provide a useful model for how they work.
The general architecture can be described by this diagram.
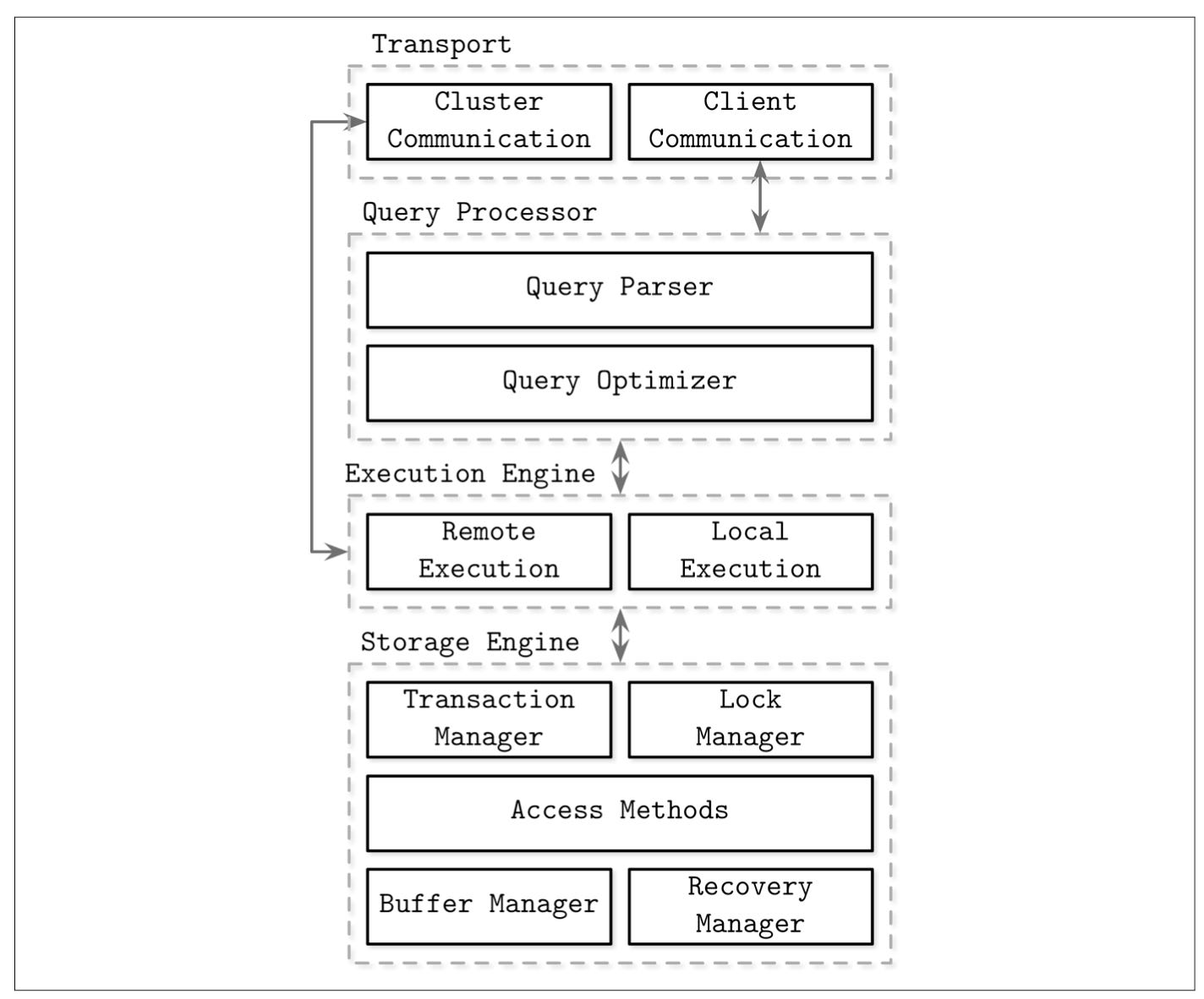
Database Management Systems use a client/server model. Your application is the client and the DBMS is the server (either hosted on the same machine or on a different machine).
The Transport system is how the DBMS accepts client requests.
Client requests come in the form of a database query and are usually expressed in some type of a query language (ex. SQL).
After receiving the query, the Transport system will pass the query on to the Query Processor.
The Query Processor will first parse the query (using an Abstract Syntax Tree for ex.) and make sure it is valid.
Checking for validity means making sure that the query makes sense (all the commands are recognized, the data accessed is valid, etc.) and also that the client is correctly permissioned to access/modify the data that they’re requesting.
If the query isn’t valid, then the database will return an error to the client.
Otherwise, the parsed query is passed to the Query Optimizer.
The optimizer will first eliminate redundant parts of the query and then use internal database statistics (index cardinality, approximate intersection size, etc.) to find the most efficient way to execute the query.
For distributed databases, the optimizer will also consider data placement like which node in the cluster holds the data and the costs associated with the transfer.
The output from the Optimizer is an Execution Plan that describes the optimal method of executing the query. This plan is also called the Query Plan or Query Execution Plan.
This execution plan gets passed on to the Execution Engine which carries out the plan.
When you’re using a distributed database, the execution plan can involve remote execution (making network requests for data that is stored on a different machine).
Otherwise, it’s just local execution (carrying out queries for data that is stored locally).
Remote execution involves Cluster Communication, where the DBMS communicates with other machines in the database cluster and sends them requests for data. As you can see in the diagram above, that’s part of the Transport layer.
Local execution involves talking to the Storage Engine to get the data.
The Storage Engine is the component in the database that is directly responsible for storing, retrieving and managing data in memory and on disk.
Storage Engines typically provide a simple data manipulation API (allowing for CRUD features) and contain all the logic for the actual details of how to manipulate the data.
Examples of Storage Engines include BerkeleyDB, LevelDB, RocksDB, etc.
Databases will often allow you to pick the Storage Engine that’s being used.
MySQL, for example, has several choices for the storage engine, including RocksDB and InnoDB.
The Storage Engine consists of several components
Transaction Manager - responsible for creating transaction objects and managing their atomicity (either the entire transaction succeeds or it is rolled back).
Lock Manager - Transactions will be executing concurrently, so the Lock Manager manages the locks on database objects being accessed by each transaction (and releasing those locks when the transaction either commits or rolls back).
Access Methods - These manage access, compression and organizing data on disk. Access methods include heap files and storage structures such as B-trees.
Buffer Manager - This manager caches data pages in RAM to reduce the number of accesses to disk.
Recovery Manager - Maintains the operation log and restoring the system state in case of a failure.
Different Storage Engines make different tradeoffs between these components resulting in differing performance for things like compression, scaling, partitioning, speed, etc.
For more, be sure to check out Database Internals by Alex Petrov.
Quastor is a free Software Engineering newsletter that sends out summaries of technical blog posts, deep dives on interesting tech and FAANG interview questions and solutions.
Tech Snippets
How to build a second brain as a software engineer - A second brain is a personal knowledge management system (PKM) that you can use to organize your thoughts and references. Two popular ways of doing this are Zettelkasten and The PARA method.
This article goes through how to build your own PKM so you can become a better engineer.
Extreme HTTP Performance Tuning - Marc Richards managed to squeeze out 1.2 million JSON API requests per second from an 4 vCPU AWS EC2 instance.
He breaks down how he was able to do it in this detailed blog post.
How to Secure Anything - This is an amazing github repo on Security Engineering.
It goes through various security models, security tools (cryptography, tamper detection, access control, etc.), and also links resources on how real world systems are secured.
Turns out there’s an entire series of textbooks on how to secure nuclear facilities!
An Inside Look at Modern Web Browsers - A fantastic 4-part blog series on how the Chrome browser works. It goes from the high level architecture to the inner workings of the rendering process and the compositor.
Interview Question
You are given a dictionary of words.
Write a function that finds the longest word in the dictionary that is made up of other words in the list.
Input: words = ["w","wo","wor","worl","world"]
Output: "world"
Explanation: The word "world" can be built one character at a time by "w", "wo", "wor", and "worl". Here’s the question in LeetCode.
Previous Solution
As a reminder, here’s our last question
Given a positive integer n, write a function that computes the number of trailing zeros in n!
Trailing zeros are all the zeros that come at the end of a number.
For example, 20,300 has 2 trailing zeros.
Example
Input - 12
Output - 2
Explanation - 12! is 479001600
Input - 900
Output - 224
Explanation - 900! is a big ass number
Here’s the question in LeetCode.
Solution
This is actually a really interesting question in number theory with a very elegant solution. You can solve it by breaking a number down into its prime factorization.
Brilliant.org has an awesome explanation that gives you an intuition for how this works.
The basic overview is that you break a number down into its prime factorization, count the number of 2s and 5s in the prime factorization.
For every pair of 2s and 5s, that will multiply to a 10 which adds an additional trailing zero to the final product.

The number of 2s in the prime factorization of n! will be more than the number of 5s, so the number of zeros can be determined by counting the number of 5s. All of those 5s can be assumed to match with a 2.
A really cool way of counting the number of 5s in the prime factorization of n! is with a simple summation as illustrated in this theorem.

Read the brilliant article for intuition on how they got that formula.
Here’s the Python 3 code.
