


The Engineering Behind Stripe's Fraud Detection System
Five books that changed my software engineering career. Boost your productivity with ZSH and Alacritty. Floating Point visually explained and more!
Hey Everyone,
Today we’ll be talking about
How Stripe uses Similarity Clustering to catch Fraud Rings
The merchant fraud problem at Stripe
Picking Gradient Boosted Decision Trees and training the models
Using the models to predict fraud.
Plus, a couple awesome tech snippets on
Five Books that Changed My Software Engineering Career
Boost Your Productivity with ZSH and Alacritty
Floating Point Visually Explained
Benchmarking Various Databases
We also have a solution to our last coding interview question, plus a new question from Google.
Quastor Daily is a free Software Engineering newsletter sends out FAANG Interview questions (with detailed solutions), Technical Deep Dives and summaries of Engineering Blog Posts.
How Stripe uses Similarity Clustering to catch Fraud Rings
Stripe is one of the world’s largest payment processors.
The company’s main product is the Stripe Payments API, which developers can use to easily embed payment functionality into their applications.
Due to Stripe’s scale, they’re a big target for payments fraud and cybercrime.
Andrew Tausz is part of the Risk Intelligence team at Stripe, and he wrote a great blog post on how Stripe uses similarity clustering to catch fraud rings.
Merchant Fraud at Stripe
One of the most common types of fraud that Stripe faces is merchant fraud, where a scammer will create a website that advertises fraudulent products or services (and uses Stripe to process payments).
An example might be if a scammer creates a website that sells electronic goods at a highly discounted price. After a customer pays him for the good, he pockets the money and doesn’t send the customer the promised good.
The customer will end up issuing a chargeback through their credit card, which will eventually get paid back by Stripe.
Stripe will then attempt to debit the account of the scammer, but if they’re unable to (the scammer transferred out all his money) then Stripe will have to eat the losses.
After a fraudster gets caught by Stripe, his account will be disabled. But, it’s quite likely that he’ll try to continue the scam by creating a new Stripe account.
One way Stripe can reduce fraud is by catching these repeat fraudsters through similarity clustering.
Using Similarity Clustering to Reduce Merchant Fraud
When a scammer creates a new Stripe account (after getting caught on his previous account), he’ll probably reuse some information and attributes from his previous account.
Certain information is easy to fabricate, like your name or date of birth. But, other attributes are more difficult. For example, it takes significant effort to obtain a new bank account.
Therefore, Stripe has found that linking accounts together via shared attributes is quite effective at catching obvious fraud attempts.
Switching from Heuristics-based to an ML model
In order to link accounts together, Stripe relies on a similarity score.
They take two accounts and then assign them a similarity score based on the number of shared attributes the accounts have.
Some shared attributes are weighed more heavily than others. Two Stripe accounts who share dates of birth should have a lower similarity score than two accounts who share a bank account.
Previously, Stripe relied on a heuristic based system where the weightings were hand-constructed (based on guess and check).
Stripe decided to switch by training a machine learning model to handle this task.
Now, they can automatically retrain the model over time as they obtain more data and improve in accuracy, adapt to new fraud trends, and learn the signatures of particular adversarial groups.
Building the ML Model
To build the model, Stripe followed a supervised learning approach.
The approach Stripe took to build the model is Similarity Learning, where the objective is to learn a similarity function that can measure how similar two objects are.
Similarity learning is used extensively in ranking, recommendation systems, face/voice verification, and fraud detection.
They already had a massive dataset of fraud rings and clusters of fraudulent accounts based on prior work from their risk underwriting team.
Stripe cleaned that into a dataset consisting of pairs of accounts along with a label for each pair indicating whether or not the two accounts belong to the same cluster.
Now that they had the dataset, Stripe had to generate features that the model could use to compare the pair of accounts.
Creating a Stripe account requires quite a bit of data, so Stripe had a large feature set they could utilize.
Examples of features chosen include the account’s email domain, overlap in credit card numbers used for both accounts, measure of text similarity, and more.
Using gradient-boosted decision trees
Due to the huge range of features, Stripe decided to go with gradient-boosted decision trees (GBDTs) to represent their similarity model.
Stripe found that GBDTs strike the right balance between being easy to train, having strong predictive power, and being robust despite variations in the data.
GBDTs are also straightforward to fine-tune and have well-understood properties.
The implementation of GBDTs that Stripe used was XGBoost.
Stripe chose XGBoost models because of their great performance and also because Stripe already had well-developed infrastructure to train and support them.
Stripe has an internal API called Railyard that handles training ML models in a scalable and maintainable way.
You can read more about Railyard and it’s architecture here.
Prediction Use
After, Stripe began to use their model to predict fraudulent activity.
Since this model operates on pairs of Stripe accounts, it’s not possible to feed it all pairs of accounts and compute similarity scores across all pairs (there’s too many combinations).
Instead, Stripe uses some heuristics to identify suspicious accounts and prune the set of candidates to a reasonable number.
Then, they use their ML models to generate similarity scores between the accounts.
After, they compute the connected components on the resulting graph to get a final output of high-fidelity account clusters that can be analyzed, processed or manually inspected.
If a cluster contains a large amount of known fraudulent accounts, then a risk analyst may want to further investigate the remaining accounts in that cluster.
You can read more details in the full article here.
Quastor Daily is a free Software Engineering newsletter sends out FAANG Interview questions (with detailed solutions), Technical Deep Dives and summaries of Engineering Blog Posts.
Tech Snippets
Five Books that Changed My Career as a Software Engineer - Juliano Lima wrote a blog post on 5 books he recommends to all software engineers. Here’s a list of the books.
The Passionate Programmer: Creating a Remarkable Career in Software Development by Chad Fowler - This book is about career development and it has a lot of insights on how to perform better as a programmer and explore the best opportunities for you.
The Pragmatic Programmer - your journey to mastery by David Thomas and Andrew Hunt - This book is a masterpiece that discusses topics ranging from software architecture to career development and personal responsibility
Unwritten Laws of Engineering by W.J. King - This book is a classic, written in 1944. It’s amazing to understand the corporate structure and how you should behave to improve your professional effectiveness.
Remote: Office Not Required by David Heinemeier Hansson and Jason Fried - This is a great book on how to do remote work effectively. It’s opinionated and presents the knowledge about what worked for DHH and Fried’s company.
Explain the Cloud Like I’m 10 by Todd Hoff - This is a brilliant book on cloud services and it explains what goes on under the hood when you watch something on Netflix.
The book is a great explain of how to present software engineering concepts to a non-technical audience, so it’s a great way to learn how to structure technical presentations for non-developers at your company.
Read the full blog post for Juliano’s reviews of each book.
Boost your productivity with ZSH and Alacritty - Z Shell is an extended variant of bash that comes with a bunch of useful features and extensions.
Alacritty is a terminal emulator written in Rust that is benchmarked as the fastest terminal emulator out there.
This is a great blog post that delves into ZSH and Alacritty and goes through a setup.
Floating Point Visually Explained - An awesome blog post by Fabien Sanglard that gives a visual explanation of Floating Point numbers. Most explanations rely on mathematical formulas but Fabien goes a different way that makes it easier to understand.
Database Benchmark - This github repo builds the same application (a basic chat app) with 6 different databases (Firebase Firestore, AWS Amplify Datastore, and a couple others).
The post then goes through various benchmarks to see how the databases stack up against each other.
Interview Question
You are given a character array containing a set of words separated by whitespace.
Your task is to modify that character array so that the words all appear in reverse order.
Do this without using any extra space.
Example
input - ['A', 'l', 'i', 'c', 'e', ' ', 'l', 'i', 'k', 'e', 's', ' ', 'B', 'o', 'b']
output - ['B', 'o', 'b', ' ', 'l', 'i', 'k', 'e', 's', ' ', 'A', 'l', 'i', 'c', 'e']
We’ll send the solution in our next email, so make sure you move our emails to primary, so you don’t miss them!
Gmail users—move us to your primary inbox
On your phone? Hit the 3 dots at the top right corner, click "Move to" then "Primary"
On desktop? Back out of this email then drag and drop this email into the "Primary" tab near the top left of your screen
A pop-up will ask you “Do you want to do this for future messages from quastor@substack.com” - please select yes
Apple mail users—tap on our email address at the top of this email (next to "From:" on mobile) and click “Add to VIPs”
Quastor Daily is a free Software Engineering newsletter sends out FAANG Interview questions (with detailed solutions), Technical Deep Dives and summaries of Engineering Blog Posts.
Previous Solution
As a reminder, here’s our last question
You are given an array of k linked lists.
Each list is sorted in ascending order.
Merge all the linked lists into one sorted linked list and return it.
Here’s the question in LeetCode.
Solution
We can solve this question with Divide and Conquer.
We start with k linked lists and we merge every pair (using the combineLists function).
This leaves us with k/2 remaining linked lists.
We can then recursively call our function on the remaining k/2 linked lists where we combine every pair to result in k/4 linked lists, k/8 linked lists, and so on.
We continue this process until we reach our final linked list.
If we have an odd number of linked lists to combine, then we just ignore the last linked lists and add it to the merged list to be combined in the next combination step.
The number of times we have to repeat the combination step (until we reach the final linked list) scales with log(k).
The number of nodes we will be traversing for each combination step scales with k*N, where N is the average number of nodes in our linked lists and k is the number of linked lists.
This is because we’ll have to “look at” every node in all the linked lists, and there are k*N total nodes.
Therefore, our time complexity is O(k*N*log(k)).
Here’s the Python 3 code.
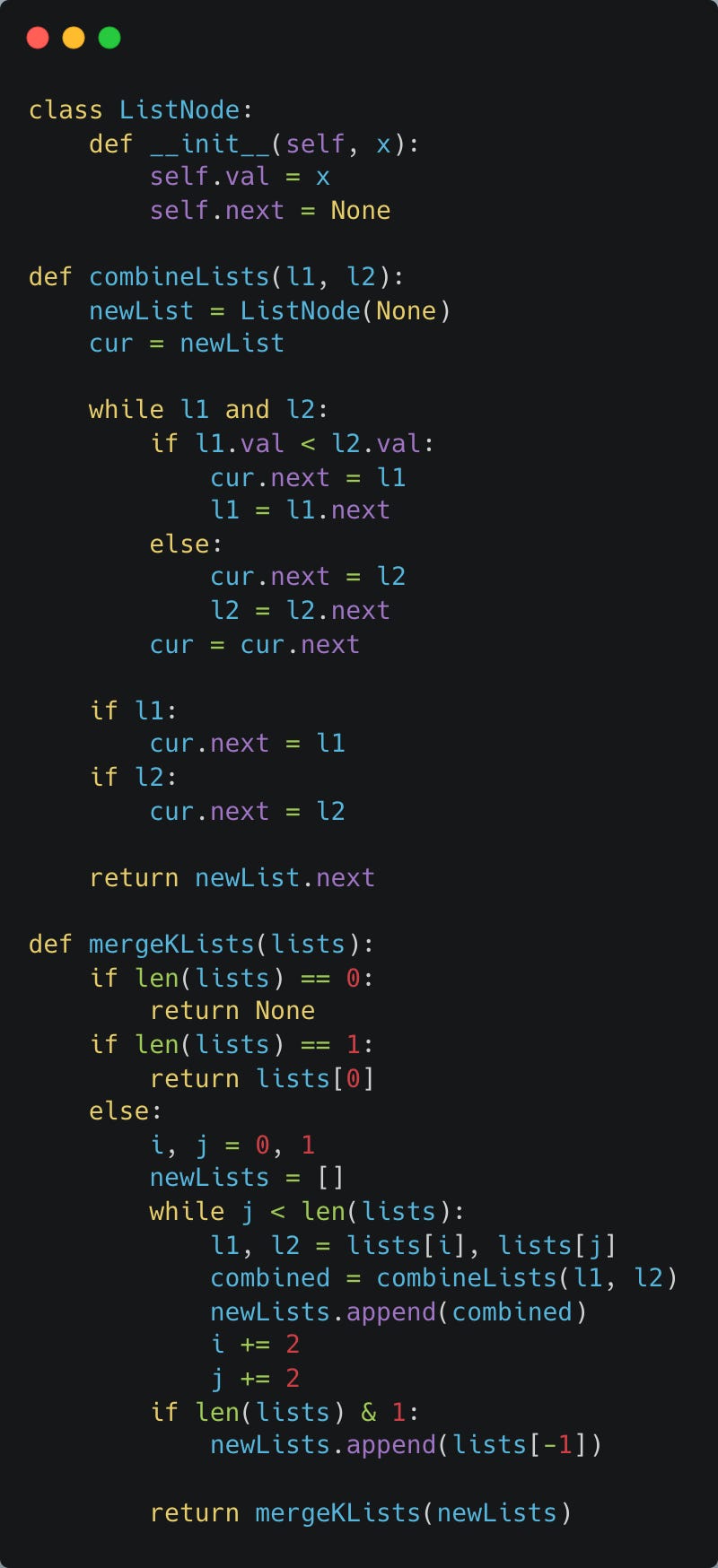
For the solution, I decided to sacrifice on space complexity to make the solution more readable and easily understandable.
If you’d like to see the optimal solution (and to read other solutions), check this article out.